作者:掘金@小希子:https://juejin.cn/post/7175739649451622460
一、前言
这一篇博文主要讲一下我们spring是怎么解决循环依赖的问题的。
二、什么是循环依赖
首先我们需要明确,什么是循环依赖呢?这里举一个简单的例子:
@Service
public class A {
@Autowired
private B b;
}
@Service
public class B {
@Autowired
private A a;
}
以这个例子来看,我们声明了a、b两个bean,且a中需要注入一个b,b中需要注入一个a。
结合我们上篇博文的bean生命周期的知识,我们来模拟一下这两个bean创建的流程:
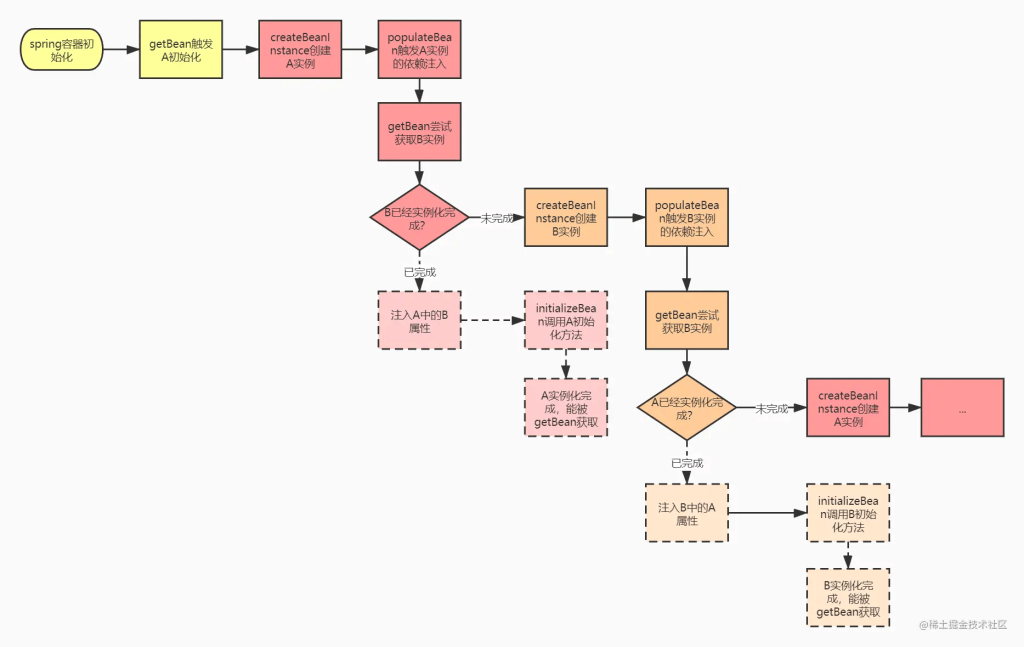
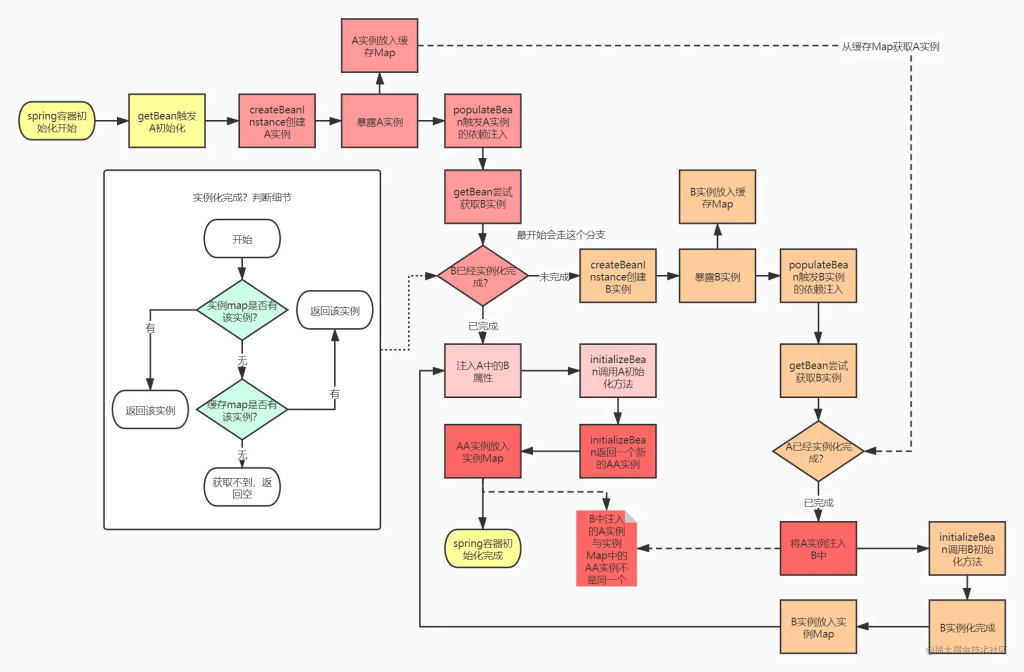
如果没有缓存的设计,我们的虚线所示的分支将永远无法到达,导致出现无法解决的循环依赖问题….
三、三级缓存设计
1. 自己解决循环依赖问题
现在,假如我们是spring的架构师,我们应该怎么解决这个循环依赖问题呢?
1.1. 流程设计
首先如果要解决这个问题,我们的目标应该是要把之前的级联的无限创建流程切到,也就是说我们的流程要变为如下所示:
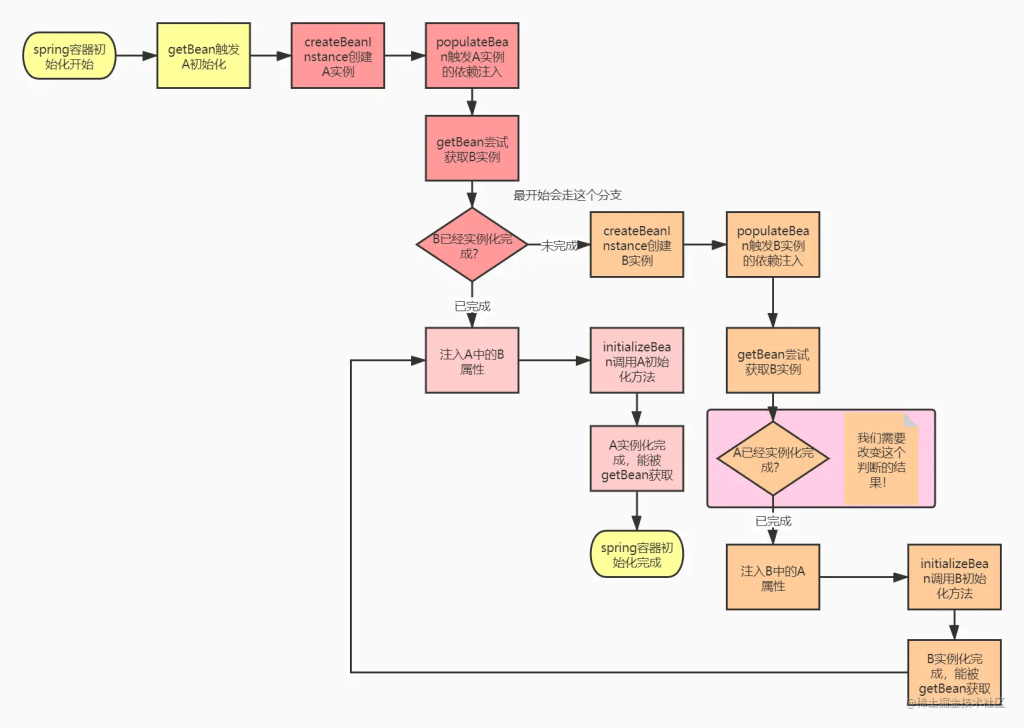
也就是说,我们需要在B实例创建后,注入A的时候,能够拿到A的实例,这样才能打破无限创建实例的情况。
而B实例的初始化流程,是在A实例创建之后,在populateBean方法中进行依赖注入时触发的。那么如果我们B实例化过程中,想要拿到A的实例,那么A实例必须在createBeanInstance创建实例后(实例都没有就啥也别说了)、populateBean方法调用之前,就暴露出去,让B能通过getBean获取到!(同学们认真想一下这个流程,在现有的流程下改造,是不是只能够这样操作?自己先想清楚这个流程,再去结合spring源码验证,这一块的知识点你以后想忘都忘不掉)
那么结合我们的思路,我们再修改一下流程图:
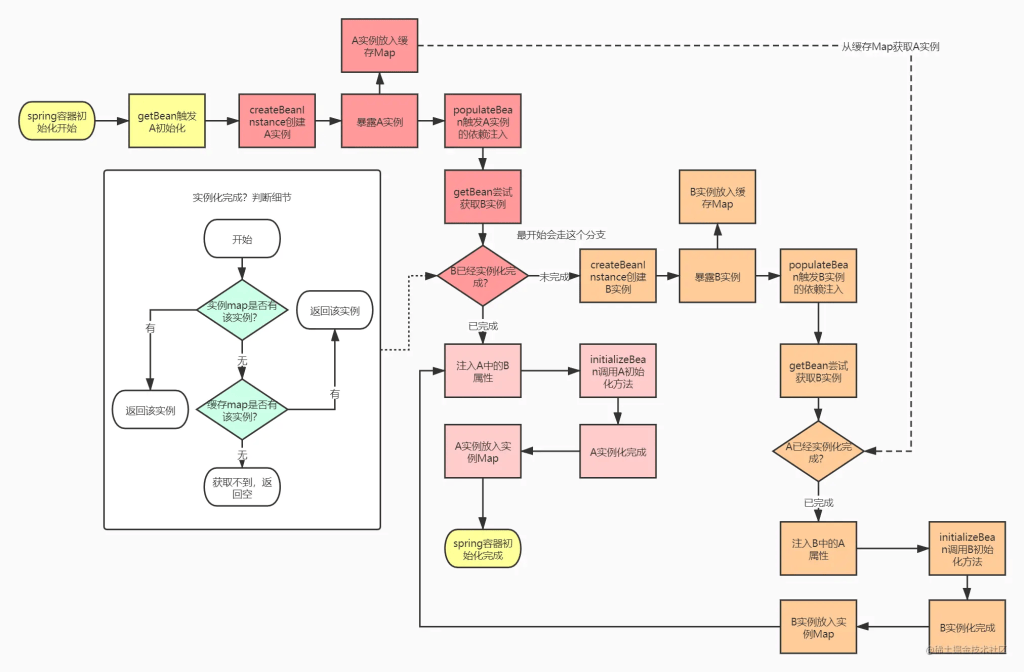
1.2. 伪代码实现
流程已经设计好了,那么我们其实也可以出一下这个流程的伪代码(伪代码就不写加锁那些流程了):
// 正真已经初始化完成的map
private Map<String, Object> singleMap = new ConcurrentHashMap<>(16);
// 缓存的map
private Map<String, Object> cacheMap = new ConcurrentHashMap<>(16);
protected Object getBean(final String beanName) {
// 先看一下目标bean是否完全初始化完了,完全初始化完直接返回
Object single = singleMap.get(beanName);
if (single != null) {
return single;
}
// 再看一下目标bean实例是否已经创建,已经创建直接返回
single = cacheMap.get(beanName);
if (single != null) {
return single;
}
// 创建实例
Object beanInstance = createBeanInstance(beanName);
// 实例创建之后,放入缓存
// 因为已经创建实例了,这个时候这个实例的引用暴露出去已经没问题了
// 之后的属性注入等逻辑还是在这个实例上做的
cacheMap.put(beanName, beanInstance);
// 依赖注入,会触发依赖的bean的getBean方法
populateBean(beanName, beanInstance);
// 初始化方法调用
initializeBean(beanName, beanInstance);
// 从缓存移除,放入实例map
singleMap.put(beanName, beanInstance);
cacheMap.remove(beanName)
return beanInstance;
}
可以看到,如果我们自己实现一个缓存结构来解决循环依赖的问题的话,可能只需要两层结构就可以了,但是spring却使用了3级缓存,它有哪些不一样的考量呢?
2. Spring源码
我们已经知道该怎么解决循环依赖问题了,那么现在我们就一起看一下spring源码,看一下我们的分析是否正确。
由于之前我们已经详细讲过整个bean的生命周期了,所以这里就只挑三级缓存相关的代码段来讲了,会跳过比较多的代码,同学们如果有点懵,可以温习一下万字长文讲透bean的生命周期。
2.1. Spring的三级缓存设计
2.1.1. 三级缓存源码
首先,在我们的AbstractBeanFactory#doGetBean的逻辑中:
// 初始化是通过getBean触发bean创建的,依赖注入最终也会使用getBean获取依赖的bean的实例
public Object getBean(String name) throws BeansException {
return doGetBean(name, null, null, false);
}
protected <T> T doGetBean(final String name, @Nullable final Class<T> requiredType,
@Nullable final Object[] args, boolean typeCheckOnly) throws BeansException {
final String beanName = transformedBeanName(name);
Object bean;
// 获取bean实例
Object sharedInstance = getSingleton(beanName);
if (sharedInstance != null && args == null) {
// beanFactory相关,之后再讲
bean = getObjectForBeanInstance(sharedInstance, name, beanName, null);
}
else {
// 跳过一些代码
// 创建bean的逻辑
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
// 跳过一些代码
}
// 跳过一些代码
// 返回bean实例
return (T) bean;
}
可以看到,如果我们使用getSingleton(beanName)直接获取到bean实例了,是会直接把bean实例返回的,我们一起看一下这个方法(这个方法属于DefaultSingletonBeanRegistry):
// 一级缓存,缓存正常的bean实例
/** Cache of singleton objects: bean name to bean instance. */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
// 二级缓存,缓存还未进行依赖注入和初始化方法调用的bean实例
/** Cache of early singleton objects: bean name to bean instance. */
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
// 三级缓存,缓存bean实例的ObjectFactory
/** Cache of singleton factories: bean name to ObjectFactory. */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
public Object getSingleton(String beanName) {
return getSingleton(beanName, true);
}
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 先尝试中一级缓存获取
Object singletonObject = this.singletonObjects.get(beanName);
// 获取不到,并且当前需要获取的bean正在创建中
// 第一次容器初始化触发getBean(A)的时候,这个isSingletonCurrentlyInCreation判断一定为false
// 这个时候就会去走创建bean的流程,创建bean之前会先把这个bean标记为正在创建
// 然后A实例化之后,依赖注入B,触发B的实例化,B再注入A的时候,会再次触发getBean(A)
// 此时isSingletonCurrentlyInCreation就会返回true了
// 当前需要获取的bean正在创建中时,代表出现了循环依赖(或者一前一后并发获取这个bean)
// 这个时候才需要去看二、三级缓存
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
// 加锁了
synchronized (this.singletonObjects) {
// 从二级缓存获取
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
// 二级缓存也没有,并且允许获取早期引用的话 - allowEarlyReference传进来是true
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
// 从三级缓存获取ObjectFactory
if (singletonFactory != null) {
// 通过ObjectFactory获取bean实例
singletonObject = singletonFactory.getObject();
// 放入二级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
// 从三级缓存删除
// 也就是说对于一个单例bean,ObjectFactory#getObject只会调用到一次
// 获取到早期bean实例之后,就把这个bean实例从三级缓存升级到二级缓存了
this.singletonFactories.remove(beanName);
}
}
}
}
// 不管从哪里获取到的bean实例,都会返回
return singletonObject;
}
一二级缓存都好理解,其实就可以理解为我们伪代码里面的那两个Map,但是这个三级缓存是怎么回事?ObjectFactory又是个什么东西?我们就先看一下这个ObjectFactory的结构:
@FunctionalInterface
public interface ObjectFactory<T> {
// 好吧,就是简简单单的一个获取实例的函数接口而已
T getObject() throws BeansException;
}
我们回到这个三级缓存的结构,二级缓存是是在getSingleton方法中put进去的,这跟我们之前分析的,创建bean实例之后放入,好像不太一样?那我们是不是可以推断一下,其实创建bean实例之后,是放入三级缓存的呢(总之实例创建之后是需要放入缓存的)?我们来跟一下bean实例化的代码,主要看一下上一篇时刻意忽略掉的地方:
// 代码做了很多删减,只把主要的逻辑放出来的
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
// 创建bean实例
BeanWrapper instanceWrapper = createBeanInstance(beanName, mbd, args);
final Object bean = instanceWrapper.getWrappedInstance();
// beanPostProcessor埋点调用
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
// 重点是这里了,如果是单例bean&&允许循环依赖&&当前bean正在创建
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
// 加入三级缓存
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
Object exposedObject = bean;
try {
// 依赖注入
populateBean(beanName, mbd, instanceWrapper);
// 初始化方法调用
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
catch (Throwable ex) {
throw new BeanCreationException(...);
}
if (earlySingletonExposure) {
// 第二个参数传false是不会从三级缓存中取值的
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
// 如果发现二级缓存中有值了 - 说明出现了循环依赖
if (exposedObject == bean) {
// 并且initializeBean没有改变bean的引用
// 则把二级缓存中的bean实例返回出去
exposedObject = earlySingletonReference;
}
}
}
try {
// 注册销毁逻辑
registerDisposableBeanIfNecessary(beanName, bean, mbd);
}
catch (BeanDefinitionValidationException ex) {
throw new BeanCreationException(...);
}
return exposedObject;
}
可以看到,初始化一个bean是,创建bean实例之后,如果这个bean是单例bean&&允许循环依赖&&当前bean正在创建,那么将会调用addSingletonFactory加入三级缓存:
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
// 加入三级缓存
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
也就是说我们伪代码中的这一段有了:
// 创建实例
Object beanInstance = createBeanInstance(beanName);
// 实例创建之后,放入缓存
// 因为已经创建实例了,这个时候这个实例的引用暴露出去已经没问题了
// 之后的属性注入等逻辑还是在这个实例上做的
cacheMap.put(beanName, beanInstance);
那么接下来,完全实例化完成的bean又是什么时候塞入我们的实例Map(一级缓存)singletonObjects的呢?
这个时候我们就要回到调用createBean方法的这一块的逻辑了:
if (mbd.isSingleton()) {
// 我们回到这个位置
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
可以看到,我们的createBean创建逻辑是通过一个lamdba语法传入getSingleton方法了,我们进入这个方法看一下:
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
synchronized (this.singletonObjects) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
// 一级缓存拿不到
// 注意一下这个方法,这里会标记这个bean正在创建
beforeSingletonCreation(beanName);
boolean newSingleton = false;
try {
// 调用外部传入的lamdba,即createBean逻辑
// 获取到完全实例化好的bean
// 需要注意的是,这个时候这个bean的实例已经在二级缓存或者三级缓存中了
// 三级缓存:bean实例创建后放入的,如果没有循环依赖/并发获取这个bean,那会一直在三级缓存中
// 二级缓存:如果出现循环依赖,第二次进入getBean->getSingleton的时候,会从三级缓存升级到二级缓存
singletonObject = singletonFactory.getObject();
// 标记一下
newSingleton = true;
}
catch (IllegalStateException ex) {
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
throw ex;
}
}
catch (BeanCreationException ex) {
throw ex;
}
finally {
// 这里是从正在创建的列表移除,到这里这个bean要么已经完全初始化完成了
// 要么就是初始化失败,都需要移除的
afterSingletonCreation(beanName);
}
if (newSingleton) {
// 如果是新初始化了一个单例bean,加入一级缓存
addSingleton(beanName, singletonObject);
}
}
return singletonObject;
}
}
哈哈,加入实例Map(一级缓存)singletonObjects的逻辑明显就是在这个addSingleton中了:
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
// 这个逻辑应该一点也不意外吧
// 放入一级缓存,从二、三级缓存删除,这里就用判断当前bean具体是在哪个缓存了
// 反正都要删的
this.singletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
也就是说,我们伪代码的这一块在spring里面也有对应的体现,完美:
// 初始化方法调用
initializeBean(beanName, beanInstance);
// 从缓存移除,放入实例map
singleMap.put(beanName, beanInstance);
cacheMap.remove(beanName)
就这样,spring通过缓存设计解决了循环依赖的问题。
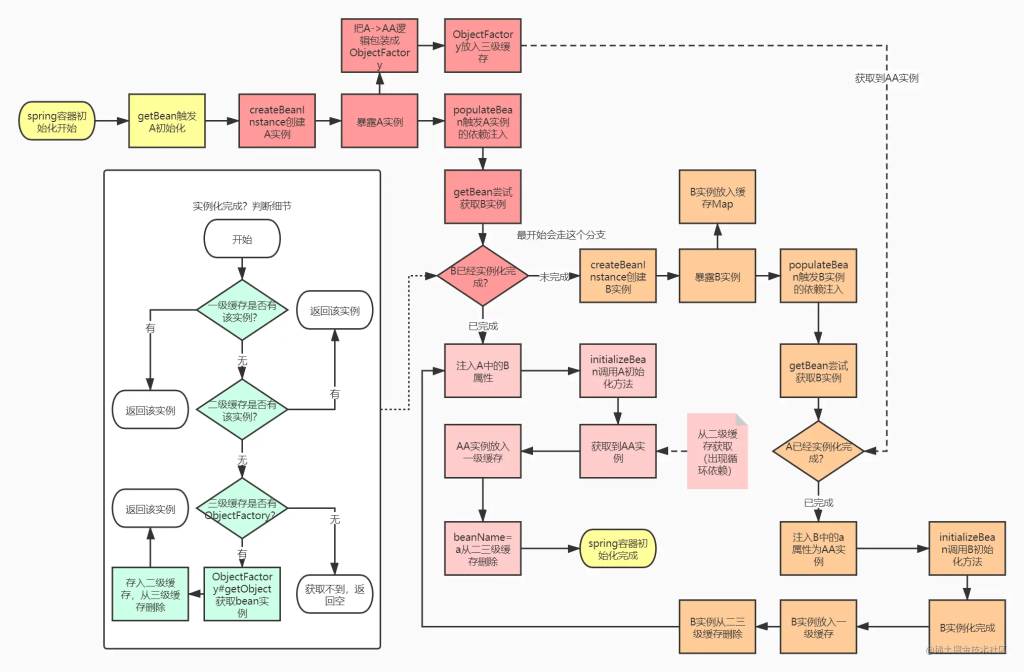
2.1.2. 三级缓存解决循环依赖流程图
什么,看完代码之后还是有点模糊?那么把我们的流程图再改一下,按照spring的流程来:
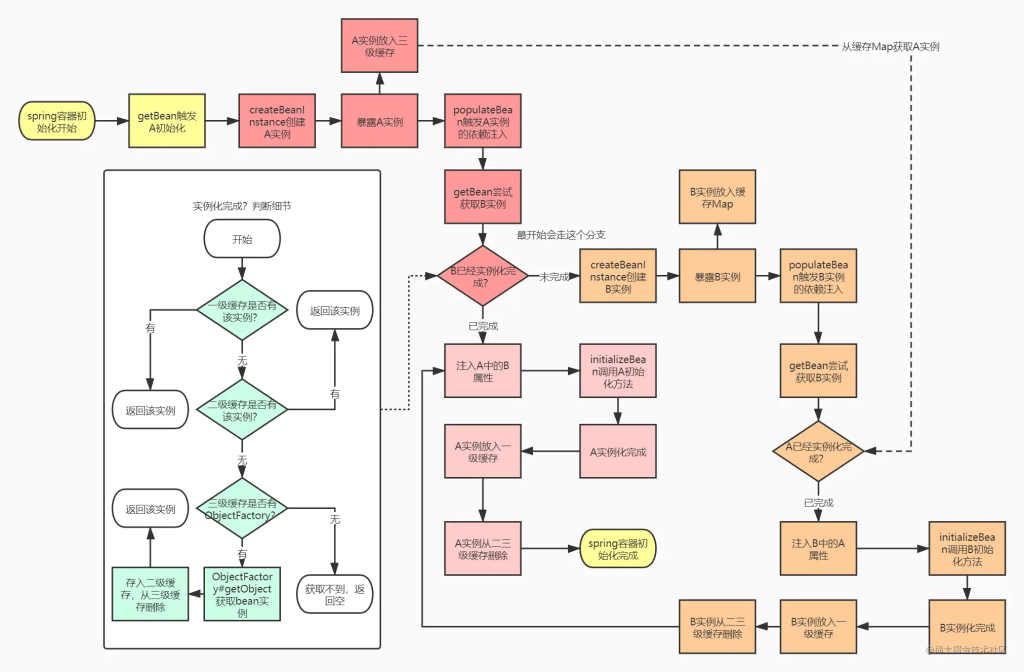
2.1.3. 三级缓存解决循环依赖伪代码
看完图还觉得不清晰的话,我们把所有spring中三级缓存相关的代码汇总到一起,用伪代码的方式,拍平成一个方法,大家应该感觉会更清晰了:
// 一级缓存
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
// 二级缓存
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
// 三级缓存
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
protected Object getBean(final String beanName) {
// !以下为getSingleton逻辑!
// 先从一级缓存获取
Object single = singletonObjects.get(beanName);
if (single != null) {
return single;
}
// 再从二级缓存获取
single = earlySingletonObjects.get(beanName);
if (single != null) {
return single;
}
// 从三级缓存获取objectFactory
ObjectFactory<?> objectFactory = singletonFactories.get(beanName);
if (objectFactory != null) {
single = objectFactory.get();
// 升到二级缓存
earlySingletonObjects.put(beanName, single);
singletonFactories.remove(beanName);
return single;
}
// !以上为getSingleton逻辑!
// !以下为doCreateBean逻辑
// 缓存完全拿不到,需要创建
// 创建实例
Object beanInstance = createBeanInstance(beanName);
// 实例创建之后,放入三级缓存
singletonFactories.put(beanName, () -> return beanInstance);
// 依赖注入,会触发依赖的bean的getBean方法
populateBean(beanName, beanInstance);
// 初始化方法调用
initializeBean(beanName, beanInstance);
// 依赖注入完之后,如果二级缓存有值,说明出现了循环依赖
// 这个时候直接取二级缓存中的bean实例
Object earlySingletonReference = earlySingletonObjects.get(beanName);
if (earlySingletonReference != null) {
beanInstance = earlySingletonObject;
}
// !以上为doCreateBean逻辑
// 从二三缓存移除,放入一级缓存
singletonObjects.put(beanName, beanInstance);
earlySingletonObjects.remove(beanName);
singletonFactories.remove(beanName);
return beanInstance;
}
把所有逻辑放到一起之后会清晰很多,同学们只需要自行模拟一遍,再populateBean中再次调用getBean逻辑进行依赖注入,应该就能捋清楚了。
2.1.4. 标记当前bean正在创建
在我们刚刚看到的将bean实例封装成ObjectFactory并放入三级缓存的流程中,有一个判断是当前bean是正在创建,这个状态又是怎么判断的呢:
// 重点是这里了,如果是单例bean&&允许循环依赖&&当前bean正在创建
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
// 加入三级缓存
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
我们看一下这个isSingletonCurrentlyInCreation的逻辑:
private final Set<String> singletonsCurrentlyInCreation =
Collections.newSetFromMap(new ConcurrentHashMap<>(16));
public boolean isSingletonCurrentlyInCreation(String beanName) {
return this.singletonsCurrentlyInCreation.contains(beanName);
}
可以看到额,其实就是判断当前beanName是不是在这个singletonsCurrentlyInCreation容器中,那么这个容器中的值又是什么时候操作的呢?
希望同学们还记得getSingleton(beanName, singletonFactory)中有调用的beforeSingletonCreation和afterSingletonCreation:
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
synchronized (this.singletonObjects) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
// 一级缓存拿不到
// 注意一下这个方法,这里会标记这个bean正在创建
beforeSingletonCreation(beanName);
boolean newSingleton = false;
try {
// 调用外部传入的lamdba,即createBean逻辑
singletonObject = singletonFactory.getObject();
// 标记一下
newSingleton = true;
}
catch (BeanCreationException ex) {
throw ex;
}
finally {
// 这里是从正在创建的列表移除,到这里这个bean要么已经完全初始化完成了
// 要么就是初始化失败,都需要移除的
afterSingletonCreation(beanName);
}
if (newSingleton) {
// 如果是新初始化了一个单例bean,加入一级缓存
addSingleton(beanName, singletonObject);
}
}
return singletonObject;
}
}
我们现在来看一下这两个方法的逻辑:
protected void beforeSingletonCreation(String beanName) {
// 加入singletonsCurrentlyInCreation,由于singletonsCurrentlyInCreation是一个set
// 如果加入失败的话,说明在创建两次这个bean
// 这个时候会抛出循环依赖异常
if (!this.inCreationCheckExclusions.contains(beanName) && !this.singletonsCurrentlyInCreation.add(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
}
protected void afterSingletonCreation(String beanName) {
// 从singletonsCurrentlyInCreation中删除
if (!this.inCreationCheckExclusions.contains(beanName) && !this.singletonsCurrentlyInCreation.remove(beanName)) {
throw new IllegalStateException("Singleton '" + beanName + "' isn't currently in creation");
}
}
可以看到,我们这两个方法主要就是对singletonsCurrentlyInCreation容器进行操作的,inCreationCheckExclusions这个容器可以不用管它,这名称一看就是一些白名单之类的配置。
这里需要主要的是beforeSingletonCreation中,如果singletonsCurrentlyInCreation.add(beanName)失败的话,是会抛出BeanCurrentlyInCreationException的,这代表spring遇到了无法解决的循环依赖问题,此时会抛出异常中断初始化流程,毕竟单例的bean不允许被创建两次。
2.2. 为什么要设计为三级结构?
2.2.1. 只做两级缓存会有什么问题?
其实到这里,我们已经清楚,三级缓存的设计已经成功的解决了循环依赖的问题。
可是按我们自己的设计思路,明明只需要两级缓存就可以解决,spring却使用了三级缓存,难道是为了炫技么?
这个时候,就需要我们再细致的看一下bean初始化过程了:
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
// ...
if (earlySingletonExposure) {
// 放入三级缓存
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
Object exposedObject = bean;
try {
populateBean(beanName, mbd, instanceWrapper);
// 这里这个引用被替换了
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
// ...
return exposedObject;
}
仔细观察,initializeBean方法是可能返回一个新的对象,从而把createBeanInstance创建的bean实例替换掉的:
protected Object initializeBean(final String beanName, final Object bean, @Nullable RootBeanDefinition mbd) {
// 调用aware接口
invokeAwareMethods(beanName, bean);
Object wrappedBean = bean;
if (mbd == null || !mbd.isSynthetic()) {
// 埋点
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
}
try {
// 初始化方法
invokeInitMethods(beanName, wrappedBean, mbd);
}
catch (Throwable ex) {
throw new BeanCreationException(...);
}
if (mbd == null || !mbd.isSynthetic()) {
// 埋点
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
}
return wrappedBean;
}
可以看到,我们的postProcessBeforeInitialization和postProcessAfterInitialization的埋点方法都是有可能把我们的bean替换掉的。
那么结合整个流程来看,由于我们放入缓存之后,initializeBean方法中可能存在替换bean的情况,如果只有两级缓存的话:
这会导致B中注入的A实例与singletonObjects中保存的AA实例不一致,而之后其他的实例注入a时,却会拿到singletonObjects中的AA实例,这样肯定是不符合预期的。
2.2.2. 三级缓存是如何解决问题的
那么这个问题应该怎么解决呢?
这个时候我们就要回到添加三级缓存的地方看一下了。addSingletonFactory的第二个参数就是一个ObjectFactory,并且这个ObjectFactory最终将会放入三级缓存,现在我们再回头看调用addSingletonFactory的地方:
// 加入三级缓存
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
熟悉lamdba语法的同学都知道,getEarlyBeanReference其实就是放入三级缓存中的ObjectFactory的getObject方法的逻辑了,那我们一起来看一下,这个方法是做了什么:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
// 调用了beanPostProcessor的一个埋点方法
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
// 返回的是埋点替换的bean
return exposedObject;
}
咦,这里也有个埋点,可以替换掉bean的引用。
原来为了解决initializeBean可能替换bean引用的问题,spring就设计了这个三级缓存,他在第三级里保存了一个ObjectFactory,其实具体就是getEarlyBeanReference的调用,其中提供了一个getEarlyBeanReference的埋点方法,通过这个埋点方法,它允许开发人员把需要替换的bean,提早替换出来。
比如说如果在initializeBean方法中希望把A换成AA(这个逻辑肯定是通过某个beanPostProcessor来做的),那么你这个beanPostProcessor可以同时提供getEarlyBeanReference方法,在出现循环依赖的时候,可以提前把A->AA这个逻辑做了,并且initializeBean方法不再做这个A->AA的逻辑,并且,当我们的循环依赖逻辑走完,A创建->注入B->触发B初始化->注入A->执行缓存逻辑获取AA实例并放入二级缓存->B初始化完成->回到A的初始化逻辑时,通过以下代码:
protected Object doCreateBean(...) {
populateBean(beanName, mbd, instanceWrapper);
Object exposedObject = initializeBean(beanName, exposedObject, mbd);
if (earlySingletonExposure) {
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
if (exposedObject == bean) {
// 如果二级缓存存在,直接使用二级缓存
exposedObject = earlySingletonReference;
}
}
}
return exposedObject;
}
这样就能保证当前bean中注入的AA和singletonObjects中的AA实例是同一个对象了。
将会把二级缓存中的AA直接返回,这是就能保证B中注入的AA实例与spring管理起来的最终的AA实例是同一个了。
整个流程梳理一下就是这样:
2.2.3. 三级缓存的实际应用
既然设计了这个三级缓存,那么肯定是有实际需求的,我们上面分析了一大堆,现在正好举一个例子看一下,为什么spring需要三级缓存。
我们都知道,Spring的AOP功能,是通过生成动态代理类来实现的,而最后我们使用的也都是代理类实例而不是原始类实例。而AOP代理类的创建,就是在initializeBean方法的postProcessAfterInitialization埋点中,我们直接看一下getEarlyBeanReference和postProcessAfterInitialization这两个埋点吧(具体类是AbstractAutoProxyCreator,之后讲AOP的时候会细讲):
public abstract class AbstractAutoProxyCreator extends ProxyProcessorSupport
implements SmartInstantiationAwareBeanPostProcessor, BeanFactoryAware {
private final Map<Object, Object> earlyProxyReferences = new ConcurrentHashMap<>(16);
// 如果出现循环依赖,getEarlyBeanReference会先被调用到
public Object getEarlyBeanReference(Object bean, String beanName) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
// 这个时候把当前类放入earlyProxyReferences
this.earlyProxyReferences.put(cacheKey, bean);
// 直接返回了一个代理实例
return wrapIfNecessary(bean, beanName, cacheKey);
}
public Object postProcessAfterInitialization(Object bean, String beanName) {
if (bean != null) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
// 注意这个判断,如果出现了循环依赖,这个if块是进不去的
if (this.earlyProxyReferences.remove(cacheKey) != bean) {
// 如果没有出现循环依赖,会在这里创建代理类
return wrapIfNecessary(bean, beanName, cacheKey);
}
}
return bean;
}
}
就这样,Spring巧妙的使用三级缓存来解决了这个不同实例的问题。当然,如果我们需要自己开发类似代理之类的可能改变bean引用的功能时,也需要遵循getEarlyBeanReference方法的埋点逻辑,学习AbstractAutoProxyCreator中的方式,才能让spring按照我们的预期来工作。
四、三级缓存无法解决的问题
1. 构造器循环依赖
刚刚讲了很多三级缓存的实现,以及它是怎么解决循环依赖的问题的。
但是,是不是使用了三级缓存,就能解决所有的循环依赖问题呢?
当然不是的,有一个特殊的循环依赖,由于java语言特性的原因,是永远无法解决的,那就是构造器循环依赖。
比如以下两个类:
public class A {
private final B b;
public A(final B b) {
this.b = b;
}
}
public class B {
private final A a;
public B(final A a) {
this.a = a;
}
}
抛开Spring来讲,同学们你们有办法让这两个类实例化成功么?
该不会有同学说,这有何难看我的:
// 你看,这样不行么~
final A a = new A(new B(a));
不好意思,这个真的不行,不信可以去试试。从语法上来讲,java的语言特性决定了不允许使用未初始化完成的变量。我们只能无限套娃:
// 这样明显就没有解决问题,是个无限套娃的死循环
final A a = new A(new B(new A(new B(new A(new B(...))))));
所以,连我们都无法解决的问题,就不应该强求spring来解决了吧~
@Service
public class A {
private final B b;
public A(final B b) {
this.b = b;
}
}
@Service
public class B {
private final A a;
public B(final A a) {
this.a = a;
}
}
启动之后,果然报错了:
Error creating bean with name 'a': Requested bean is currently in creation: Is there an unresolvable circular reference?
2. Spring真的对构造器循环依赖束手无策么?
难道,spring对于这种循环依赖真的束手无策了么?其实不是的,spring还有@Lazy这个大杀器…只需要我们对刚刚那两个类小小的改造一下:
@Service
public class A {
private final B b;
public A(final B b) {
this.b = b;
}
public void prt() {
System.out.println("in a prt");
}
}
@Service
public class B {
private final A a;
public B(@Lazy final A a) {
this.a = a;
}
public void prt() {
a.prt();
}
}
// 启动
@Test
public void test() {
applicationContext = new ClassPathXmlApplicationContext("spring.xml");
B bean = applicationContext.getBean(B.class);
bean.prt();
}
都说了成功了,运行结果同学们也能猜到了吧:
in a prt
(同学们也可以自己尝试一下~
3. @Lazy原理
这个时候我们必须要想一下,spring是怎么通过 @Lazy来绕过我们刚刚解决不了的无限套娃问题了。
因为这里涉及到之前没有细讲的参数注入时候的参数解析问题,我这边就不带大家从入口处一步一步深入了,这边直接空降到目标代码DefaultListableBeanFactory#resolveDependency:
public Object resolveDependency(DependencyDescriptor descriptor, @Nullable String requestingBeanName,
@Nullable Set<String> autowiredBeanNames, @Nullable TypeConverter typeConverter) throws BeansException {
// 跳过...
// 这个地方是我们获取依赖的地方
// 尝试获取一个懒加载代理
Object result = getAutowireCandidateResolver().getLazyResolutionProxyIfNecessary(
descriptor, requestingBeanName);
if (result == null) {
// 如果没获取到懒加载代理,就直接去获取bean实例了,这里最终会调用getBean
result = doResolveDependency(descriptor, requestingBeanName, autowiredBeanNames, typeConverter);
}
return result;
}
我们直接看一下这个getLazyResolutionProxyIfNecessary,这个方法就是获取LazyProxy的地方了:
public class ContextAnnotationAutowireCandidateResolver extends QualifierAnnotationAutowireCandidateResolver {
@Override
@Nullable
public Object getLazyResolutionProxyIfNecessary(DependencyDescriptor descriptor, @Nullable String beanName) {
// 如果是懒加载的,就构建一个懒加载的代理
return (isLazy(descriptor) ? buildLazyResolutionProxy(descriptor, beanName) : null);
}
// 判断是否是懒加载的,主要就是判断@Lazy注解,简单看下就好了
protected boolean isLazy(DependencyDescriptor descriptor) {
for (Annotation ann : descriptor.getAnnotations()) {
Lazy lazy = AnnotationUtils.getAnnotation(ann, Lazy.class);
if (lazy != null && lazy.value()) {
return true;
}
}
MethodParameter methodParam = descriptor.getMethodParameter();
if (methodParam != null) {
Method method = methodParam.getMethod();
if (method == null || void.class == method.getReturnType()) {
Lazy lazy = AnnotationUtils.getAnnotation(methodParam.getAnnotatedElement(), Lazy.class);
if (lazy != null && lazy.value()) {
return true;
}
}
}
return false;
}
protected Object buildLazyResolutionProxy(final DependencyDescriptor descriptor, final @Nullable String beanName) {
final DefaultListableBeanFactory beanFactory = (DefaultListableBeanFactory) getBeanFactory();
// 构造了一个TargetSource
TargetSource ts = new TargetSource() {
@Override
public Class<?> getTargetClass() {
return descriptor.getDependencyType();
}
@Override
public boolean isStatic() {
return false;
}
@Override
public Object getTarget() {
// 再对应的getTarget方法里,才会去正真加载依赖,进而调用getBean方法
Object target = beanFactory.doResolveDependency(descriptor, beanName, null, null);
if (target == null) {
Class<?> type = getTargetClass();
if (Map.class == type) {
return Collections.emptyMap();
}
else if (List.class == type) {
return Collections.emptyList();
}
else if (Set.class == type || Collection.class == type) {
return Collections.emptySet();
}
throw new NoSuchBeanDefinitionException(...);
}
return target;
}
@Override
public void releaseTarget(Object target) {
}
};
// 创建代理工厂ProxyFactory
ProxyFactory pf = new ProxyFactory();
pf.setTargetSource(ts);
Class<?> dependencyType = descriptor.getDependencyType();
if (dependencyType.isInterface()) {
pf.addInterface(dependencyType);
}
// 创建返回代理类
return pf.getProxy(beanFactory.getBeanClassLoader());
}
}
同学们可能对TargetSource和ProxyFactory这些不熟悉,没关系,这不妨碍我们理解逻辑。
从源码我们可以看到,对于@Lazy的依赖,我们其实是返回了一个代理类(以下称为LazyProxy)而不是正真通过getBean拿到目标bean注入。而真正的获取bean的逻辑,被封装到了一个TargetSource类的getTarget方法中,而这个TargetSource类最终被用来生成LazyProxy了,那么我们是不是可以推测,LazyProxy应该持有这个TargetSource对象。
而从我们懒加载的语意来讲,是说真正使用到这个bean(调用这个bean的某个方法时)的时候,才对这个属性进行注入/初始化。
那么对于当前这个例子来讲,就是说其实B创建的时候,并没有去调用getBean("a")去获取构造器的参数,而是直接生成了一个LazyProxy来做B构造器的参数,而B之后正真调用到A的方法时,才会去调用TargetSource中的getTarget获取A实例,即调用getBean("a"),这个时候A早就实例化好了,所以也就不会有循环依赖问题了。
4. 伪代码描述
还是同样,我们可以用伪代码来描述一下这个流程,伪代码我们就直接用静态代理来描述了:
public class A {
private final B b;
public A(final B b) {
this.b = b;
}
public void prt() {
System.out.println("in a prt");
}
}
public class B {
private final A a;
public B(final A a) {
this.a = a;
}
public void prt() {
a.prt();
}
}
// A的懒加载代理类
public class LazyProxyA extends A {
private A source;
private final Map<String, Object> ioc;
private final String beanName;
public LazyProxyA(Map<String, Object> ioc, String beanName) {
super(null);
this.ioc = ioc;
this.beanName = beanName;
}
@Override
public void prt() {
if (source == null) {
source = (A) ioc.get(beanName);
}
source.prt();
}
}
那么整个初始化的流程简单来描述就是:
Map<String, Object> ioc = new HashMap<>();
void init() {
B b = new B(new LazyProxyA(ioc, "a"));
ioc.put("b", b);
A a = new A((B)ioc.get("b"));
ioc.put("a", a);
}
我们也模拟一下运行:
void test() {
// 容器初始化
init();
B b = (B)ioc.get("b");
b.prt();
}
当然是能成功打印的:
in a prt
六、总结
关于循环依赖的问题,Spring提供了通过设计缓存的方式来解决的,而设计为三级缓存,主要是为了解决bean初始化过程中,实例被放入缓存之后,实例的引用还可能在调用initializeBean方法时被替换的问题。
对于构造器的循环依赖,三级缓存设计是无法解决的,这属于java语言的约束;但是spring提供了一种使用@Lazy的方式,绕过这个限制,使得构造器的循环依赖在特定情况下(循环链中的某个注入打上@Lazy注解)也能解决。