

这个 ChatLaw 由北大团队发布,致力于提供普惠的法律服务。一方面当前全国执业律师不足,供给远远小于法律需求;另一方面普通人对法律知识和条文存在天然鸿沟,无法运用法律武器保护自己。
大语言模型最近的崛起正好为普通人以对话方式咨询法律相关问题提供了一个绝佳契机。
ChatLaw 共有三个版本
分别如下:
ChatLaw-13B,为学术 demo 版,基于姜子牙 Ziya-LLaMA-13B-v1 训练而来,中文各项表现很好。但是,逻辑复杂的法律问答效果不佳,需要用更大参数的模型来解决;
ChatLaw-33B,也为学术 demo 版,基于 Anima-33B 训练而来,逻辑推理能力大幅提升。但是,由于 Anima 的中文语料过少,问答时常会出现英文数据;
ChatLaw-Text2Vec,使用 93w 条判决案例做成的数据集,基于 BERT 训练了一个相似度匹配模型,可以将用户提问信息和对应的法条相匹配。
根据官方演示
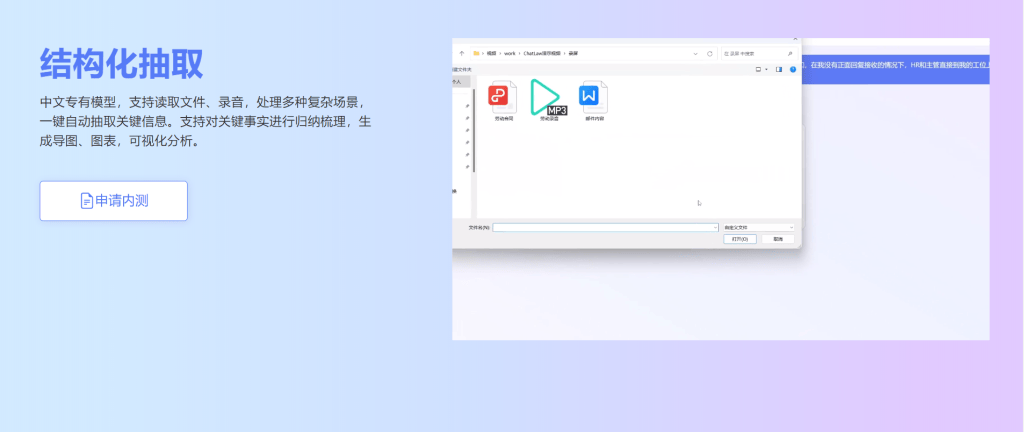
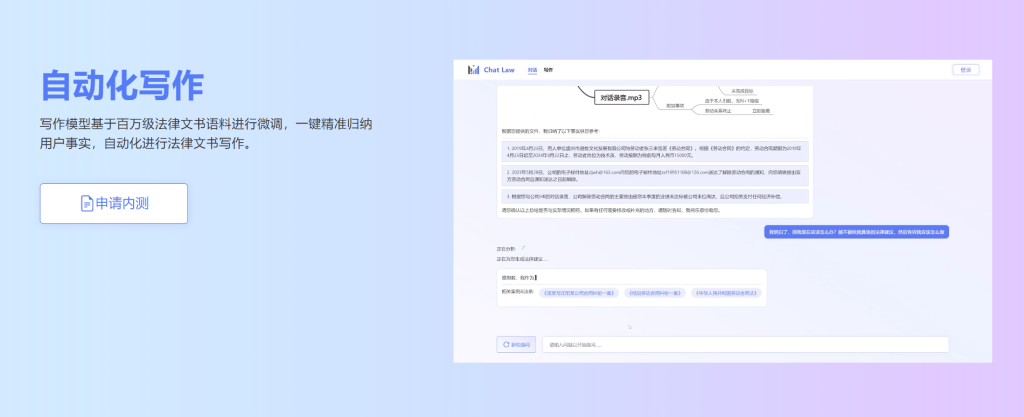
ChatLaw 支持用户上传文件、录音等法律材料,帮助他们归纳和分析,生成可视化导图、图表等。此外,ChatLaw 可以基于事实生成法律建议、法律文书。
ChatLaw 的数据来源
据了解,ChatLaw 数据主要由论坛、新闻、法条、司法解释、法律咨询、法考题、判决文书组成,随后经过清洗、数据增强等来构造对话数据。同时,通过与北大国际法学院、行业知名律师事务所进行合作,ChatLaw 团队能够确保知识库能及时更新,同时保证数据的专业性和可靠性。
ChatLaw 基于超过 2 亿的判例文书原始文本,以及 340 万条法律法规和地方政策,构建了大规模法律知识库。通过 ELO 机制进行检验,ChatLaw 模型在测试集上成功击败 GPT4,获得最高分。
在未来两个月,团队会在多个领域推出 ChatKnowledge 系列,包括政务、金融等多个领域的大模型产品。
感兴趣的朋友,快去试试吧~
官网地址:https://www.chatlaw.cloud/







没有回复内容