通过原子操作实现 redis 锁
redis 内部是通过 key/value 的形式存储的,核心原理是设置一个唯一的 key,如果这个 key 存在,说明有服务在使用
具体实现方式:
- 首先判断
redis中是否存在某个key,并且为某个值 - 如果这个
key不存在,说明当前没有服务在使用,设置key - 如果这个
key存在,说明当前有服务在使用,就等待一段时间,然后再次判断这个key是否存在
如下图所示
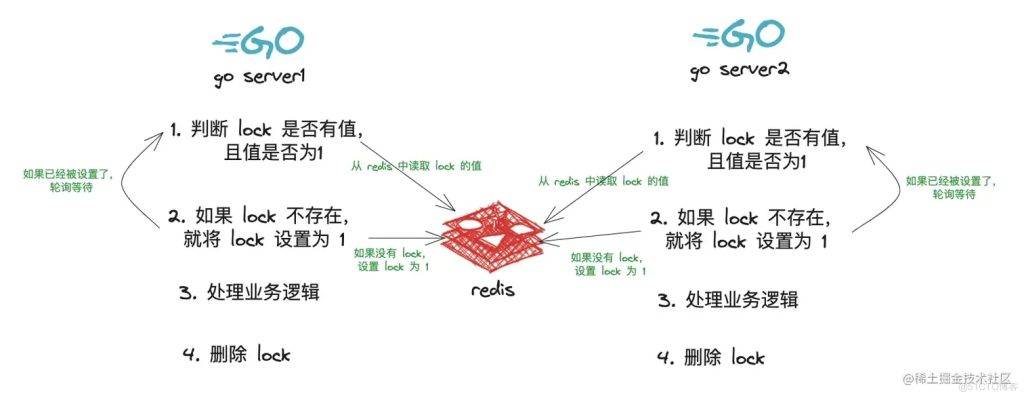
这种情况有没有问题呢?
如果在单体应用的场景下,这种方式是可行的;但是在分布式场景下,这种方式就不可行了
因为在分布式场景下,redis 是多个服务共享的,如果多个服务同时判断 key 不存在,那么就会同时设置 key,就会导致多个服务同时执行,这不是我们想要的结果
为什么这样做会有问题?
因为 get 和 set 操作不是原子操作,你先要做操作 get,然后在操作 set,这个过程中
这就会导致当第一台服务在执行 get 时,发现 key 不存在,然后进行 set,这个时候 set 可能还没有完成,第二台服务执行了 get,发现 key 不存在,然后进行 set,这个时候就会导致多个服务同时执行,这就不是原子操作了
原子操作的意思是:一次性执行,不会被打断
这个怎么做呢?
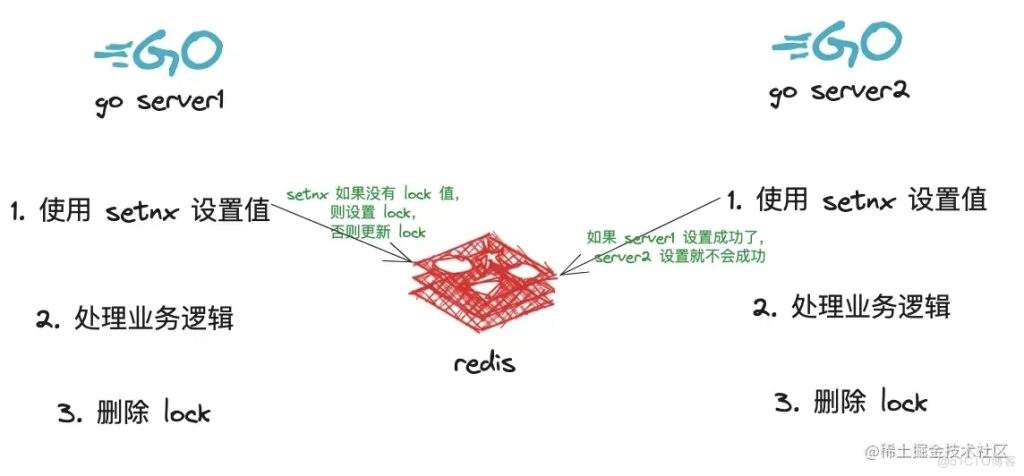
redis 提供了一个 setnx 的方法,作用是如果 key 不存在,就设置 key,设置成功返回 1,设置失败返回 0
这就将 get 和 set 的逻辑合二为一了,保证原子性了
如下图所示:
当我们了解了原理之后,看下人家是不是这样实现的,以 redsync 为例,先来看它使用,从入口函数一步步往下追
rs := redsync.New(pool)
mutexname := "my-global-mutex"
mutex := rs.NewMutex(mutexname)
if err := mutex.Lock(); err != nil {
panic(err)
}
if ok, err := mutex.Unlock(); !ok || err != nil {
panic("unlock failed")
}从上面代码可以看到,它先调用 NewMutex 创建了一个 mutex,然后调用 mutex.Lock() 方法
NewMutex 是初始化函数,用来初始化一系列的参数,
比较重要的有:
name:redis中的keygenValueFunc:生成key的函数,保证唯一性expiry:key过期的时间tries:尝试的次数,可能会拿不到锁,所以要尝试多次delayFunc:延迟时间(睡眠时间),可能会拿不到锁,就需要等一会再尝试quorum:大多数节点,这个是用来做分布式锁的,如果有5个节点,那么这里的大多数是3个节点-
m := &Mutex{ name: name, expiry: 8 * time.Second, tries: 32, delayFunc: func(tries int) time.Duration { return time.Duration(rand.Intn(maxRetryDelayMilliSec-minRetryDelayMilliSec)+minRetryDelayMilliSec) * time.Millisecond }, genValueFunc: genValue, driftFactor: 0.01, timeoutFactor: 0.05, quorum: len(r.pools)/2 + 1, pools: r.pools, }初始化结束之后,调用
m.Lock()上锁,m.Lock()方法中调用m.LockContext()方法,LockContext是核心方法,里面会做很多事情,这一步我们关心它是怎么上锁的,通过搜索发现,上锁的方法是m.acquire(),其源码是:
func (m *Mutex) acquire(ctx context.Context, pool redis.Pool, value string) (bool, error) {
conn, err := pool.Get(ctx)
if err != nil {
return false, err
}
defer conn.Close()
reply, err := conn.SetNX(m.name, value, m.expiry)
if err != nil {
return false, err
}
return reply, nil
}在这里我们清晰的看到调用 SetNX 方法
通过过期时间防止死锁
这样做完之后,还有一个问题需要解决
如果正在操作 redis 的服务挂了,那么这个 key 就会一直存在,其他服务就会等待,这样就造成了死锁
解决这个问题就是设置过期时间,如果服务挂了,过期时间到了,key 就会自动删除,其他服务就可以继续使用了
通过源代码我们可以看到它设置了一个过期时间 expiry
reply, err := conn.SetNX(m.name, value, m.expiry)这个过期时间是怎么来的呢?
刚刚在入口函数中,我们看到了 NewMutex 函数,它初始化了一个 expiry,这个 expiry 就是过期时间:expiry: 8 * time.Second,它默认设置的是 8 秒
到这里就有疑问了,如果我的服务执行时间超过 8 秒怎么办?,不就达不到锁的效果了?
我们很快就会想到,在过期前刷新下过期时间不就行了?
确实 redsync 也考虑到了这个问题,它提供了一个 Extend 方法,用来刷新过期时间
m.Extent() 方法调用 m.ExtendContext() 方法,在 m.ExtendContext() 方法中调用 m.touch() 方法
func (m *Mutex) Extend() (bool, error) {
return m.ExtendContext(nil)
}
func (m *Mutex) ExtendContext(ctx context.Context) (bool, error) {
// ... 省略其他代码
m.touch(ctx, pool, m.value, int(m.expiry/time.Millisecond))
// ... 省略其他代码
}
func (m *Mutex) touch(ctx context.Context, pool redis.Pool, value string, expiry int) (bool, error) {
// ... 省略其他代码
conn, err := pool.Get(ctx)
conn.Eval(touchScript, m.name, value, expiry)
}在 m.touch() 方法中我们看到它调用 redis 提供的 Eval 方法,可以执行一段 lua 脚本,脚本的内容如下:
var touchScript = redis.NewScript(1, `
if redis.call("GET", KEYS[1]) == ARGV[1] then
return redis.call("PEXPIRE", KEYS[1], ARGV[2])
else
return 0
end
`)它为什么要这样做呢?
不就是把过期时间刷新下吗?为什么要写 lua 呢
这里我们需要了解下 redis 的 lua 脚本,redis 的 lua 脚本是原子性的,它可以保证一段脚本的执行是原子性的
这样就可以保证刷新过期时间的操作是原子性的,不会出现刷新过期时间失败的情况
如果我们用 go 语言去续期的需要三步:
- 先获取到
key的值 - 判断
redis中的值是不是你传进来的值 - 如果是的话,续期
这样的话,这样的话就不具备原子性了,任何一步都有失败的可能,所以 redsync 选择了 lua 脚本
我们在使用 m.Extend() 续期时,需要用协程去做
那 redsync 为什么不自动续期呢?
如果做自动续期的话,当前正在操作的服务如果 hung 住了,那么就会不停的续期,造成其他服务无法进来,所以 redsync 将续期的功能交给了使用者
防止被其他服务删除
锁只能被持有该锁的服务删除,不能被其他服务删除
如果保证锁只能被持有该锁的服务删除,那么就需要在 setnx 的时候,给 key 设置一个唯一的值,这个值可以是 uuid,这样就可以保证锁只能被持有该锁的服务删除
我们看下 redsync 源码是如何做的,初始化时就生成了一个唯一的值,它是使用 base64 编码的
func genValue() (string, error) {
b := make([]byte, 16)
_, err := rand.Read(b)
if err != nil {
return "", err
}
return base64.StdEncoding.EncodeToString(b), nil
}删除的时候,调用 m.Unlock() 方法,m.Unlock() 方法调用 m.UnlockContext() 方法,在在 m.release() 方法
func (m *Mutex) release(ctx context.Context, pool redis.Pool, value string) (bool, error) {
// ... 省略其他代码
conn, err := pool.Get(ctx)
conn.Eval(deleteScript, m.name, value)
}在 m.release() 方法中我们看的也是在执行 lua 脚本,脚本的内容如下:
var deleteScript = redis.NewScript(1, `
if redis.call("GET", KEYS[1]) == ARGV[1] then
return redis.call("DEL", KEYS[1])
else
return 0
end
`)这也是为了保证在删除锁的时候,保证原子性
redlock
通过我们上面讲解的已经能满足一般的使用场景,但是在大型项目中,不会只搭建一个 redis,而是搭建 redis 集群
这样又会出现一个新的问题:redlock
redlock 是什么呢?我们先来看下 redis 集群
一般 redis 集群有一个 master 节点,多个 slave 节点
如下图所示:
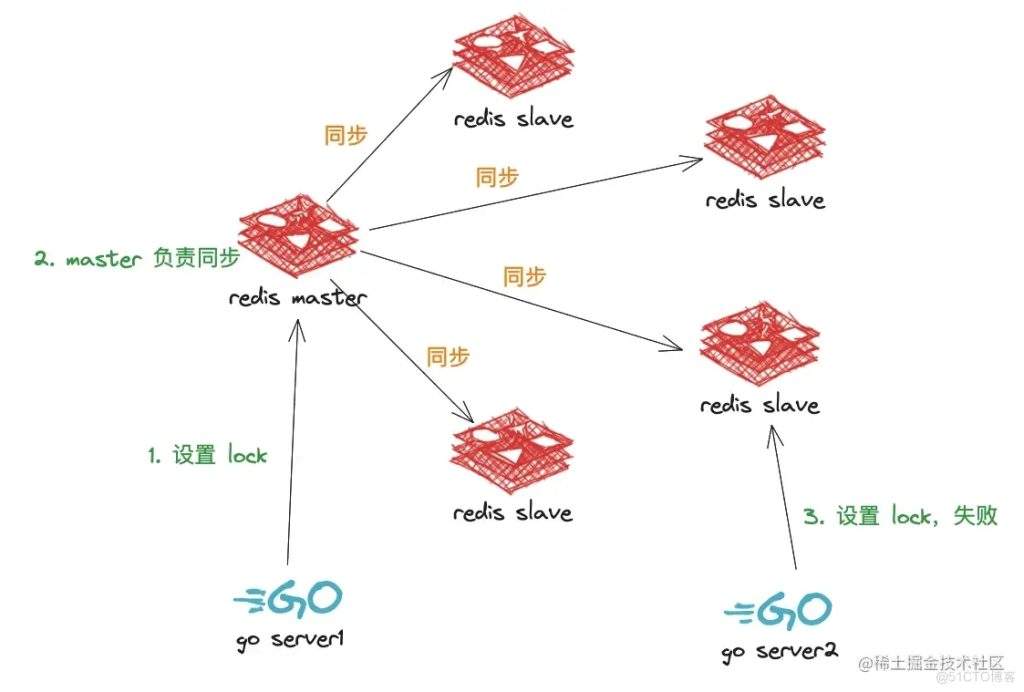
当我在加锁时,如果 master 节点会自动同步到 slave 节点,那么就不会有问题
如果这时 master 节点出问题了(或者说在同步过程中出问题,还没有同步完),slave 节点会选举出一个 master 节点,这个过程中会有一段时间,这时如果有一个服务进来写,发现是能写入的,这就出现了问题
如下图所示:
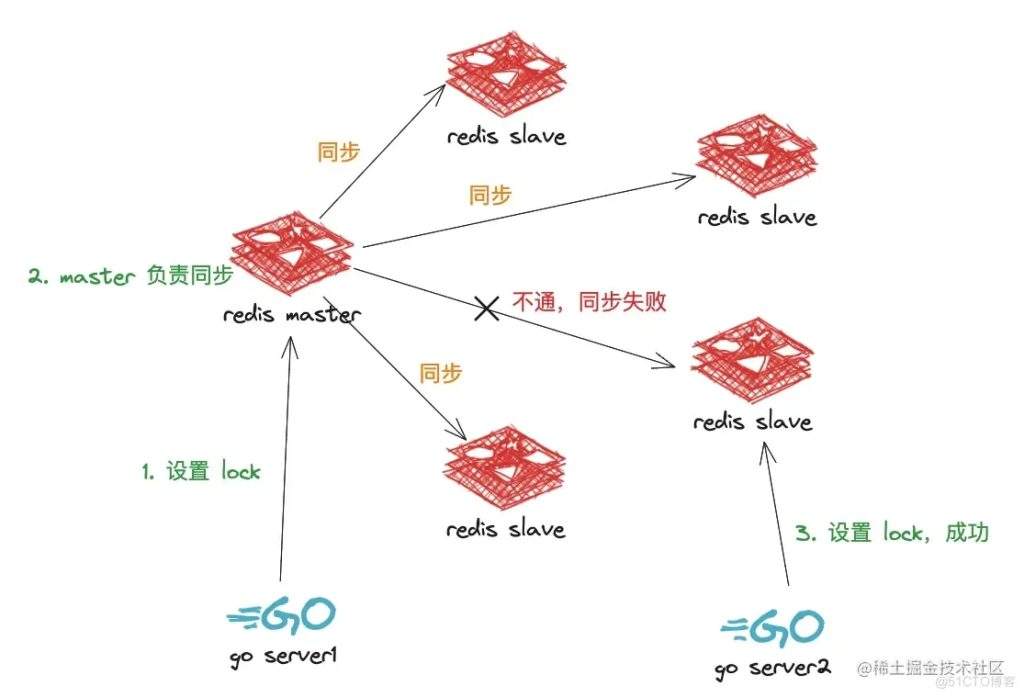
面对这种问题如何解决,引入了 redlock 的这个概念
redlock 的核心思想是:在 redis 集群中,大多数节点都能写入成功,那么就认为写入成功,而不是只向一台 redis 写入
当第一个服务写入时,同时向 5 台 redis 写入,这时如果第二个服务写入,写同时向 5 台 redis 写入,谁先成功写入大多数 redis,谁就认为写入成功,锁就交给谁
这里的大多数就是比一半多 1 台,也就是 n / 2 + 1,所以 redis 应该准备奇数台,同时也无需关心这 5 台 redis 的主从关系了
如下图所示:
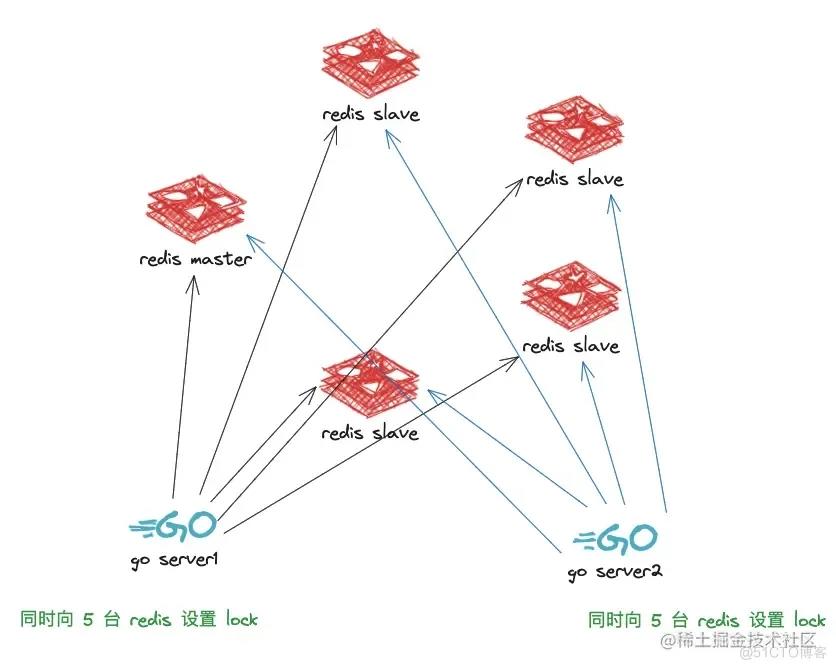
我们通过 redsync 源码来学习 redlock,是如何实现的:
- 通过
select实现超时控制 - 核心代码是
actOnPoolsAsync方法
pools:表示向多台redis写入async:表示异步写入多台redis,同步写入的话,效率偏低,使用goroutine(具体可以查看下面actOnPoolsAsync方法的分析)
- 判断是否拿到锁
- 如果拿到锁,更新
m.value和m.until - 如果没有拿到锁,需要释放已经写入的
redis的key -
func (m *Mutex) LockContext(ctx context.Context) error { if ctx == nil { ctx = context.Background() } value, err := m.genValueFunc() if err != nil { return err } // 如果没有拿到锁,等待一段时间在去拿 for i := 0; i < m.tries; i++ { if i != 0 { // 使用 select 实现超时控制 select { case <-ctx.Done(): return ErrFailed case <-time.After(m.delayFunc(i)): } } // 记录拿锁开始时间 start := time.Now() n, err := func() (int, error) { ctx, cancel := context.WithTimeout(ctx, time.Duration(int64(float64(m.expiry)*m.timeoutFactor))) defer cancel() // 异步写入多台 redis return m.actOnPoolsAsync(func(pool redis.Pool) (bool, error) { return m.acquire(ctx, pool, value) }) }() // 记录拿锁结束时间 now := time.Now() // 计算还剩多少时间:过期时间 - 拿锁花费的时间 - 时间偏移 // 这段代码是为了防止 `redis` 节点时间不同步,导致锁过期时间不准确,所以在过期时间上加上一个 `driftFactor`,这个值是 `0.01`,也就是 `1%` 的误差 until := now.Add(m.expiry - now.Sub(start) - time.Duration(int64(float64(m.expiry)*m.driftFactor))) // 判断是否竞争成功 if n >= m.quorum && now.Before(until) { m.value = value m.until = until return nil } // 如果竞争失败,释放已经写入的 redis 的 key func() (int, error) { ctx, cancel := context.WithTimeout(ctx, time.Duration(int64(float64(m.expiry)*m.timeoutFactor))) defer cancel() return m.actOnPoolsAsync(func(pool redis.Pool) (bool, error) { return m.release(ctx, pool, value) }) }() if i == m.tries-1 && err != nil { return err } } return ErrFailed }为什么要使用异步写入多台
redis呢?如果采用同步写入的多台的话,如果写入的
redis比较多,就会很耗时,可能写到最后一台redis时,前面的redis已经过期了,这样就会出现问题启用
goroutine去写入的话,可以一瞬间都拿到lock,调用setnx方法去写入然后再统计成功写入的台数,返回出去
-
func (m *Mutex) actOnPoolsAsync(actFn func(redis.Pool) (bool, error)) (int, error) { type result struct { Node int Status bool // 成功写入的台数 Err error // 未成功写入的错误 } // 启用 goroutine 去调用 setnx 写入 // 用 channel 来接收结果 ch := make(chan result) for node, pool := range m.pools { go func(node int, pool redis.Pool) { r := result{Node: node} r.Status, r.Err = actFn(pool) ch <- r }(node, pool) } n := 0 var taken []int var err error for range m.pools { r := <-ch // 写入成功,n++;写入失败,记录错误 if r.Status { n++ } else if r.Err != nil { err = multierror.Append(err, &RedisError{Node: r.Node, Err: r.Err}) } else { taken = append(taken, r.Node) err = multierror.Append(err, &ErrNodeTaken{Node: r.Node}) } } // 将写入的台数和错误返回出去 if len(taken) >= m.quorum { return n, &ErrTaken{Nodes: taken} } return n, err }总结
分布式锁的实现需要考虑的问题:
- 原子性(互斥性):锁只能被一个服务持有
- 使用
setnx命令,将set和get变成原子性 - 使用
lua搅拌
- 死锁:设置过期时间,防止服务挂了变成死锁
- 续期操作需要保证原子性,使用
lua脚本
- 安全性:锁只能被持有该锁的服务删除,不能被其他服务删除
- 在
setnx的时候,给key设置一个唯一的值
来源