sort buffer和join buffer两者没什么关系,只是最近重读了极客时间的MySQL实战,又加深了对MySQL的认知,这里记录一下sort buffer和join buffer两个知识点,以便加深印象。
sort buffer
sort buffer从名字上就可以看出肯定和排序有关,MySQL会为每个线程分配一块内存,用于排序,这个内存就称为sort buffer。
内存的大小可以通过sort_buffer_size参数控制,如果需要排序的数据量超过了sort_buffer_size的大小,就需要借助磁盘临时文件进行外部排序,一般使用归并排序算法,所以排序的数据可能需要被切分,每一份单独排序后存在临时文件中,最后将所有的文件合并成一个有序的大文件。
可以通过打开optimizer_trace,查看optimizer_trace结果中的number_of_tmp_files,判断是否使用了临时文件以及临时文件的个数。
全字段排序
假设有一个表t有name、age、city字段,在city上创建了索引,现在执行:
select city,name,age from t where city = '杭州' order by name limit 1000;
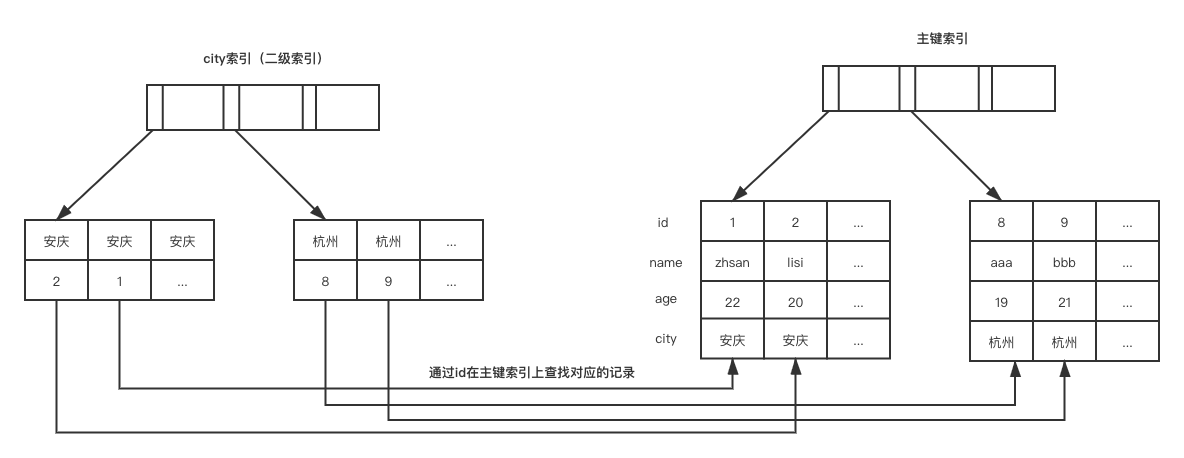
语句的执行流程:
(1)初始化sort_buffer,放入city、name、age三个字段;
(2)通过city上的索引,找到第一个city是杭州的节点,通过节点中保存的主键id去主键索引寻找该条记录,取出name、city和age字段的值,放入到sort_buffer中;
(3)继续寻找下一个满足条件的主键,通过id在主键索引中取出三个字段的值放入sort_buffer;
(4)重复步骤2和3,直到找到不满足条件的city为止;
(5)对sort_buffer中的数据按照name字段做排序;
(6)按照排序结果取前1000行返回给客户端;
rowid排序
在全字段排序中,假如select中取的字段太多,sort_buffer可能放不下,就需要借助外部排序,排序的性能会下降,max_length_for_sort_data参数可以修改排序的单行最大长度,在全字段排序中取了city、name和age字段,三个字段的数据类型长度加起来就是排序的单行长度,假设全排序中单行长度超过了max_length_for_sort_data,MySQL为了提高性能,会采用rowid排序。
rowid的排序流程:
(1)初始化sort_buffer,放入name(因为需要根据name进行排序)和id;
(2)从city索引中找到第一个city为杭州的数据的id,到主键索引中找到对应的记录,取name和id两个字段的值,放入sort_buffer;
(3)继续寻找下一个满足条件的值,将id和name放入sort_buffer;
(4)重复步骤2和3,知道找到不满足的条件的city为止;
(5)对sort_buffer中的数据按照name排序;
(6)根据排序的结果取前1000行,因为sort_buffer中只放了name和id,没有age和city,所以此时需要根据id再次从主键所以中回表取出city 、name和age的值,最后返回给客户端;
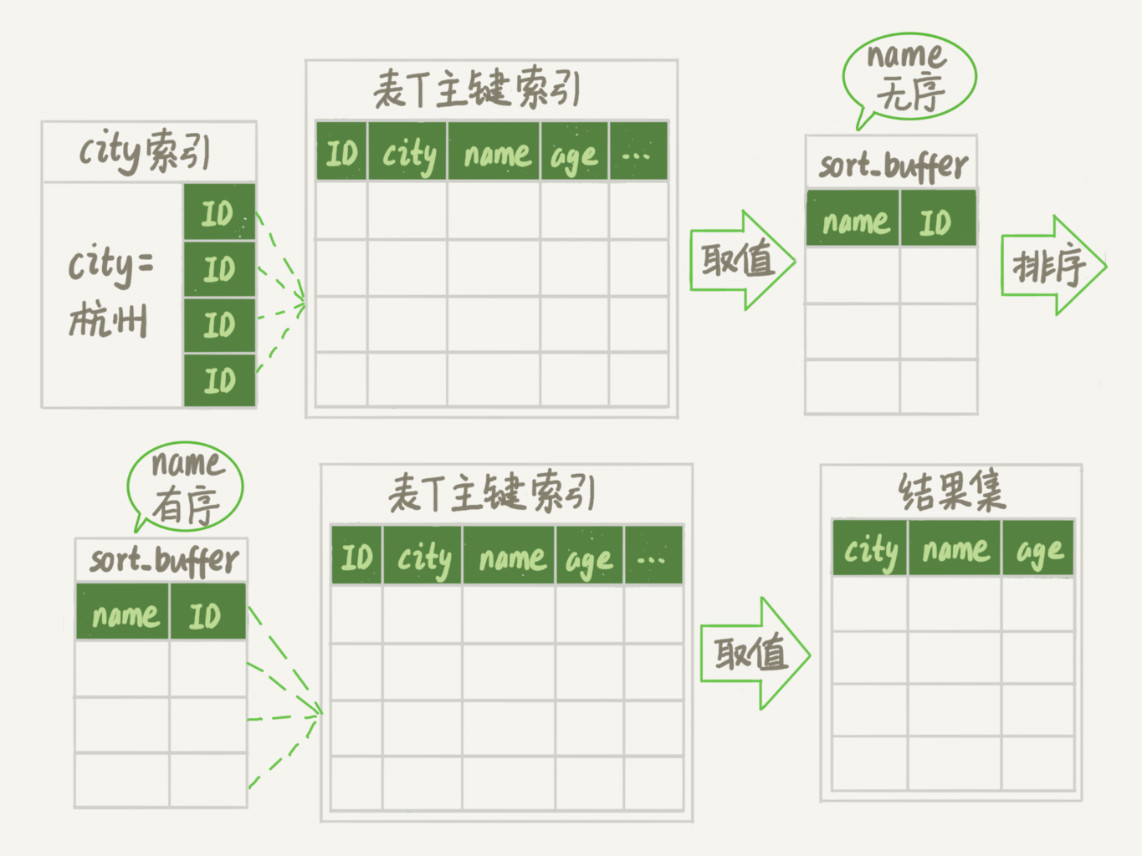
注:图片来源于极客时间-林晓斌(丁奇):MySQL实战
可以发现与字段全排序相比,rowid比字段全排序多了一次最后根据id从主键索引回表的过程。
总结:
1.如果sort_buffer足够大,会优先选择字段全排序,把需要的字段全放入sort_buffer中,排序后可直接返回结果;
2.如果sort_buffer无法满足排序的数量,会采用rowid排序算法,但是需要根据id回表查询所需的字段;
优化:
如果根据索引取到的数据就是有序的,那么就可以省去排序的过程了,所以可以在表上建一个city和name的联合索引,此时的查询流程如下:
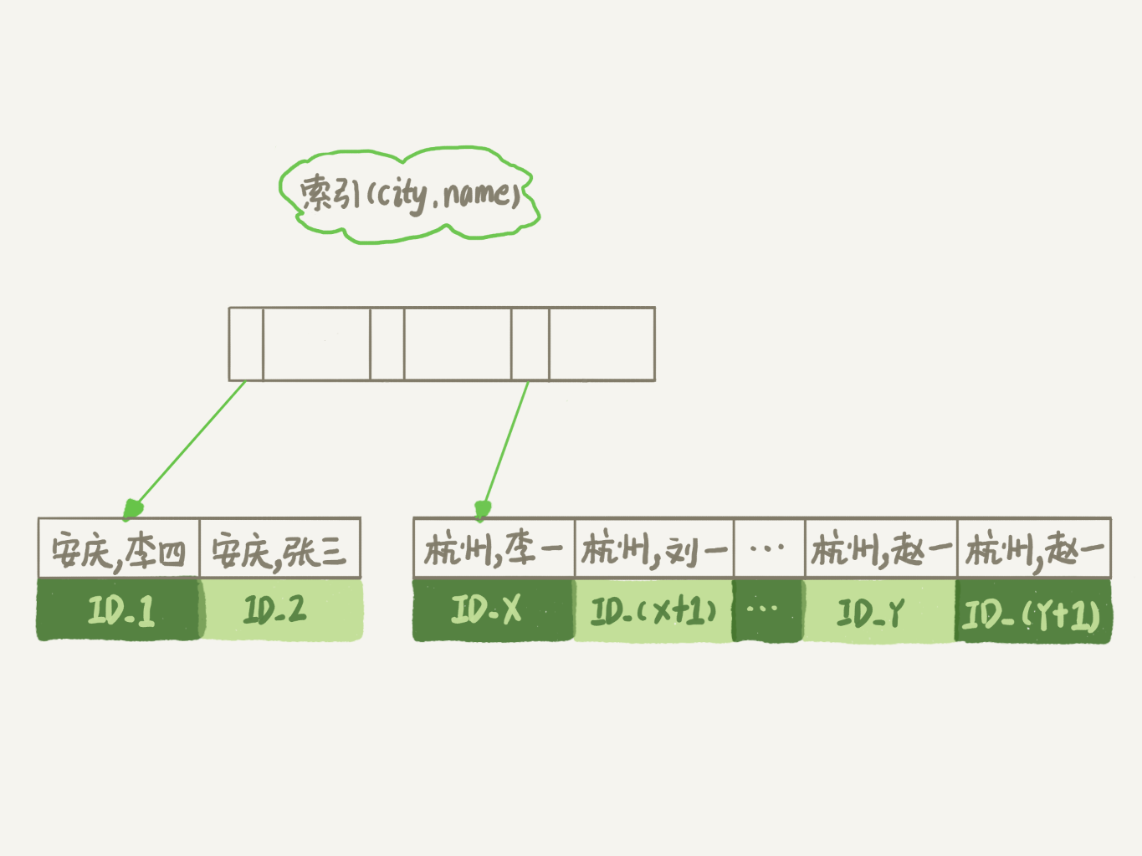
注:图片来源于极客时间-林晓斌(丁奇):MySQL实战
(1)从联合索引(city,name)中找到第一个满足city是杭州的数据的主键id;
(2)到主键索引中根据主键id取name、city、age三个字段的值,返回结果到客户端;
(3)继续取下一个记录的id;
(4)重复步骤2和3,直到第1000条记录或者不满足条件的时候为止;
可以看到如果加了city和name的联合索引,可以省去排序的过程,再继续优化,借助覆盖索引,创建city、name和age的联合索引,这样可以把回表的步骤也省掉了:
(1)从联合索引(city,name,age)中找到第一个满足city是杭州的节点,因为创建的是联合索引,索引节点中包含city、name、age的值,直接将结果集返回给客户端即可;
(2)从联合索引取下一个满足条件的记录,返回数据给客户端;
(3)重复执行步骤2,直到第1000条记录或者不满足条件为止;
join buffer
Index Nested-Loop Join(NLJ)
假设有两张表t1和t2,表结构一致,除了主键id之外只有两个字段a和b,在a字段上创建索引,然后执行语句:
select * from t1 straight_join t2 on (t1.a=t2.a);
执行流程:
(1)从表t1读入一行数据R;
(2)从数据行R中读取a字段的值,到表t2中查找,由于t2表中a字段创建了索引,所以可以借助索引在表t2中查找;
(3)将t2表中查找到满足条件的所有行,与t1做关联;
(4)重复执行步骤1到3,遍历表t1,直到所有数据被读完;
在这个过程中,t1属于驱动表,t2属于被驱动表,驱动表t1做了全表扫描,每次取出一行,然后取出字段a的值再从t2中借助索引进行查找,完成表数据行的关联,由于在被驱动表中查找时使用到了索引,所以这种查询流程称为Index Nested-Loop Join。
Simple Nested-Loop Join
修改一下查询语句,假如执行下面这个查询:
select * from t1 straight_join t2 on (t1.a=t2.b);
表t2的字段b是没有索引的,所以此时的查询流程如下:
(1)从表t1读入一行数据R;
(2)从数据行R中读取a字段的值,到表t2中查找,由于t2表中b字段没有索引,所以只能对t2进行全表扫描,查找满足条件的值;
(3)将t2表中查找到满足条件的所有行,与t1做关联;
(4)重复执行步骤1到3,遍历表t1,直到所有数据被读完;
假如驱动表的行数为N,被驱动表的行数为M,如果被驱动表上没有可用的索引,那么将会扫描NM行,可以看到在N=100,M=1000时,NM = 100000,只是这么小的数据量下就要扫描10万行,使用此算法代价会比较大,所以有了BNL算法Block Nested-Loop Join。
Block Nested-Loop Join(BNL)
在被驱动表上没有可用的索引时,BNL算法的执行流程:
(1)将表t1的数据放入线程内存join_buffer中,由于语句是select * 所以t1的所有数据会被加载到join_buffer中;
(2)扫描表t2,取出表t2的每一行,与join_buffer中的数据做对比,如果满足条件,将数据关联,作为结果集的一部分返回;
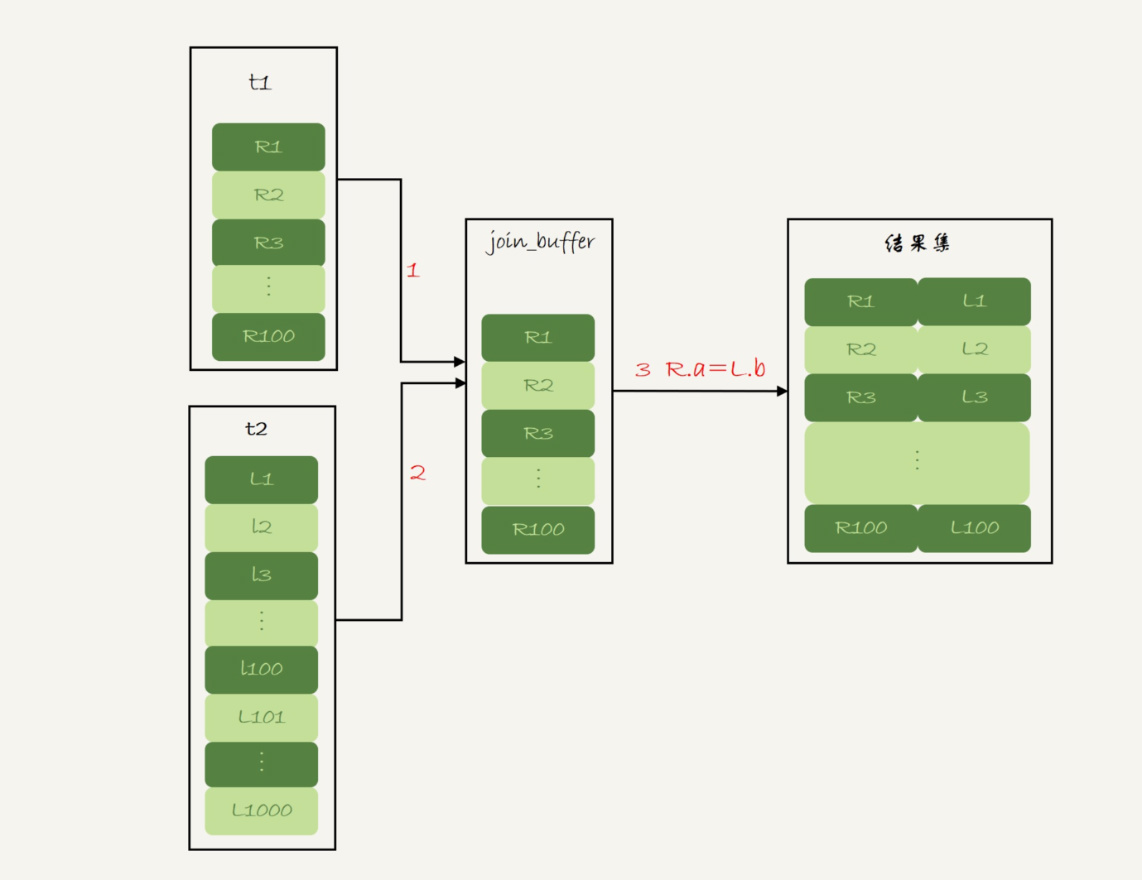
注:图片来源于极客时间-林晓斌(丁奇):MySQL实战
假设表t1的行数为N,t2的行数为M:
- 两张表都做了一次全表扫描,扫描行数是M+N;
- 表t1的每一行都要和表t2的每一行作比较,判断次数为MN,虽然还是MN但是是在内存中做的判断,因此性能会提示很多;
假如表t1的数据量太大,join_buffer中放不下,那么将会采用分段放的方式:
(1)将表t1的数据放入join_buffer中,假设在第50行的时候join_buffer满了,进行第2步;
(2)扫描表t2,取出表t2的每一行,与join_buffer中的数据做对比,如果满足条件,将数据关联,作为结果集的一部分返回;
(3)清空join_buffer;
(4)继续扫描t1,将剩余的行放入join_buffer,重复步骤1、2、3;
总结:
(1)尽量使用小表做驱动表;
(2)使用BNL算法在大表上的join操作可能要扫描被驱动表多次,占用大量的IO资源,在判断join条件时可能需要大量的判断占用CPU资源,尽量避免这种join;
(3)会导致Buffer Pool的热数据被淘汰,影响内存命中率;
Multi-Range Read 优化
我们知道,MySQL InnoDB的二级索引叶子节点中存储的是主键的值,如果需要查询其他字段的值,需要根据主键的值去主键索引上查找,才能拿到其他字段的值,这个操作称为回表,假设有一表t,在字段a上创建了索引,执行如下语句:
select * from t1 where a>=1 and a<=100;
执行流程:
(1)在字段a上建立的二级索引中找到第一个a值大于1的节点,找到对应的主键;
(2)根据主键值去主键索引中查找,获取该行记录所有字段的值,作为返回结果集;
(3)循环步骤1和2,直到把小于等于100的值全部寻找完毕;
在这个过程中,由于每次只根据一个主键ID去主键索引中查找,每次查找就变成了随机访问,性能相对较差,因为大部分数据都是按照主键递增顺序插入得到的,假如按照主键递增顺序查找的话,对磁盘的读比较接近顺序读,这样就可以提升读性能,这就是MRR优化的思路。
MRR优化后的执行流程:
(1)根据a字段上的二级索引找到所有满足条件的记录,将所有的主键ID值放入read_rnd_buffer中;
(2)将read_rnd_buffer中的id进行递增排序;
(3)根据read_rnd_buffer中排好序的id依次到主键索引中查询记录,并作为返回结果;
MRR的核心思想在于得到足够多的主键ID,然后对ID排序,再去主键索引查找数据,将随机访问改为尽量接近顺序访问。
Batched Key Access优化
MySQL在5.6版本之后引入了Batched Key Access(BKA) 算法,它可以对 Index Nested-Loop Join(NLJ) 进行优化。
NLJ算法的流程是从驱动表t1,一行一行的取出a值,再到被驱动表t2中根据字段a的索引去查找,对于表t2每次只匹配一个值,为了让t2表可以一次性多拿到一些值,可以把t1表的数据取出来之后先放到临时内存中,然后批量的去t2表的索引上去查询,我们知道在NLJ算法中并没有用到join_buffer,所以join_buffer就可以充当临时内存。
BKA算法的核心思想就是借助join_buffer批量的从被驱动表的索引中查询数据。
参考
极客时间 — 林晓斌(丁奇):MySQL实战