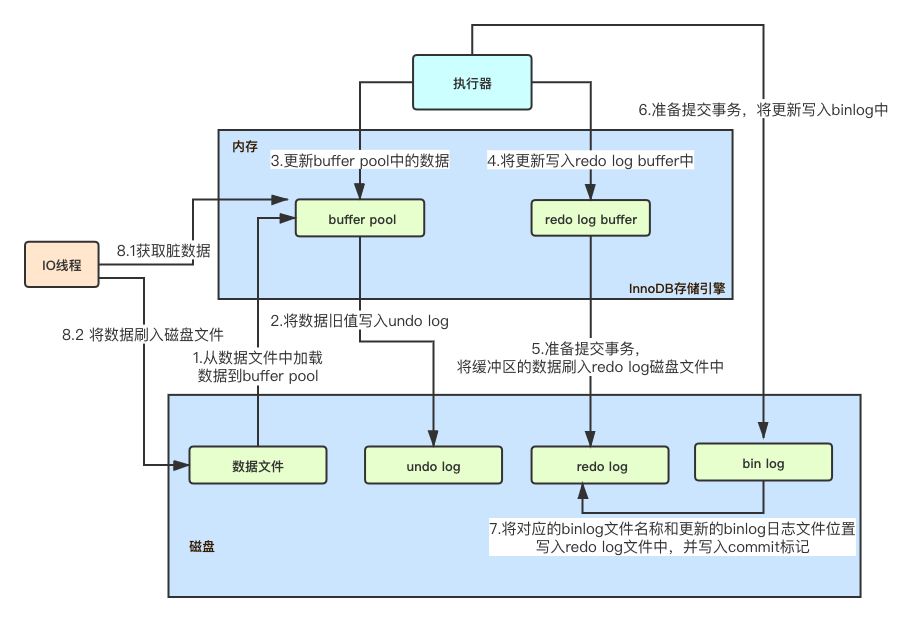
buffer pool
buffer pool缓冲池,用来缓存数据页,避免每次都从磁盘上加载数据,由于buffer pool是基于内存的,所以查询速度非常快。
undo log
undo log回滚日志,记录了SQL执行之前的旧值,用来做数据回滚。
redo log
redo log重做日志,是InnoDB存储引擎的日志,记录的是数据页的物理修改,在某个数据页上做了什么修改,用来恢复数据使用。
binlog
binlog 数据库的二进制日志,同样记录了数据的修改,binlog是MySQL的Server层实现的,所有引擎都可以使用。
- 当一条更新SQL语句执行时,首先会查看数据是否在缓冲池中,如果在更新缓冲池中的数据,如果不在,会从磁盘中将数据加载到缓冲池buffer pool(对于非唯一索引来说,可以使用change buffer,将修改先记录在change buffer中,之后再merge到原数据页)。
- 当数据加载到buffer pool中之后,首先会在undo log中记录修改前的数据,便于数据回滚。
- 更新buffer pool中的缓存数据,注意此时只是在缓存池中更新了数据,并没有更新到磁盘上,如果数据库宕机,数据会丢失。
- 将修改写入redo log中,redo log也有缓冲区redo log buffer,所以也就是会将数据先写入redo log buffer中,记录对数据的修改,由于redo log buffer也基于内存,所以此时数据库宕机依旧有丢失数据的风险。
- 提交事务,当提交事务之后,会根据一定的策略将redo log buffer的数据刷入redo log磁盘文件中,此时如果数据库宕机,重启的时候即可根据redo log文件进行数据恢复。
- 将更新内容写入binlog磁盘文件。
- 将更新对应的binlog文件名称和更新的binlog日志文件位置写入redo log文件中,并写入commit标记,用来保持redo log和binlog的一致性,此时mysql异常宕机,可以通过redo log和binlog的一致性判断是否需要恢复数据。
- 此时事务完成提交,需要注意的是此时数据只是在buffer pool中修改了,并且记录到了redo log和binlog,此时磁盘数据文件中还是旧数据,所以MySql有一个后台的IO线程,会根据配置决定何时将buffer pool中的脏数据刷新到磁盘上的数据文件中。
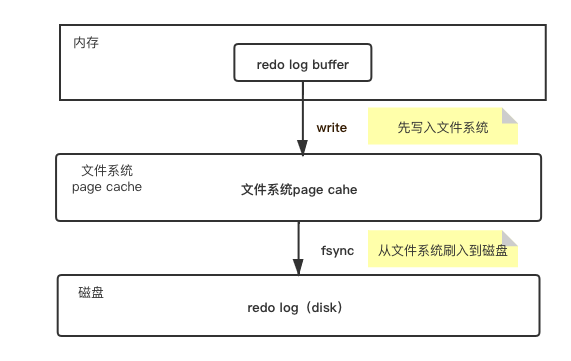
redo log的写入机制
innodb_flush_log_at_trx_commit:
- 设置为 0 的时候,表示每次事务提交时都只是把 redo log 留在 redo log buffer 中 ;
- 设置为 1 的时候,表示每次事务提交时都将 redo log 直接持久化到磁盘;
- 设置为 2 的时候,表示每次事务提交时都只是把 redo log 写到 page cache。
InnoDB 有一个后台线程,每隔 1 秒,就会把 redo log buffer 中的日志,调用 write 写到文件系统的 page cache,然后调用 fsync 持久化到磁盘。
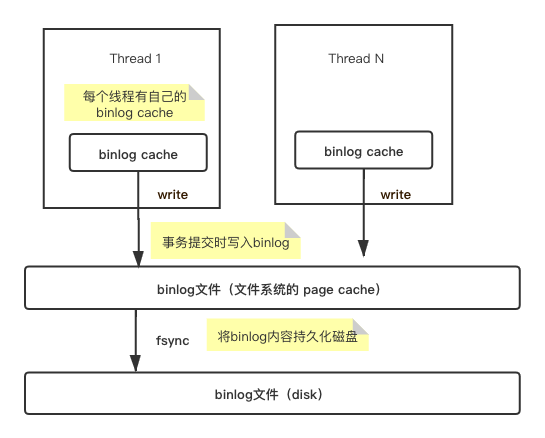
binlog的写入机制
系统为每个线程分配一片内存为binlog做缓存(binlog cache),事务执行过程中,先将内容写入binlog cache,当事务提交时,会把binlog cache写到binlog文件中,然后清空binlog cache,由于binlog存储在文件系统的 page cache,并没有持久化到磁盘,所以系统根据sync_binlog的配置判断何时将binlog文件的内容fsync到磁盘。
binlog_cache_size:
在事务写入binlog cache时,一个事务的binlog是不能被拆分的,需要确保一次性写入,binlog_cache_size用于控制binlog cache的大小。
sync_binlog:
- sync_binlog=0 的时候,表示每次提交事务都只 write,不 fsync;
- sync_binlog=1 的时候,表示每次提交事务都会执行 fsync;
- sync_binlog=N(N>1) 的时候,表示每次提交事务都 write,但累积 N 个事务后才 fsync。
change buffer
我们知道,更新一条数据的时候,如果数据页就在buffer pool中,直接更新buffer pool中的数据,如果数据页不在buffer pool中,对于非唯一索引来说,由于不需要检查唯一性,InnoDb会将这些更新操作先缓存在change buffer中,可以避免从磁盘中加载数据页,减少磁盘的IO,在下次需要访问这个数据页的数据时,再从磁盘加载到内存,将changer buffer中的更新操作应用到原数据页中,这个过程被称为merge:
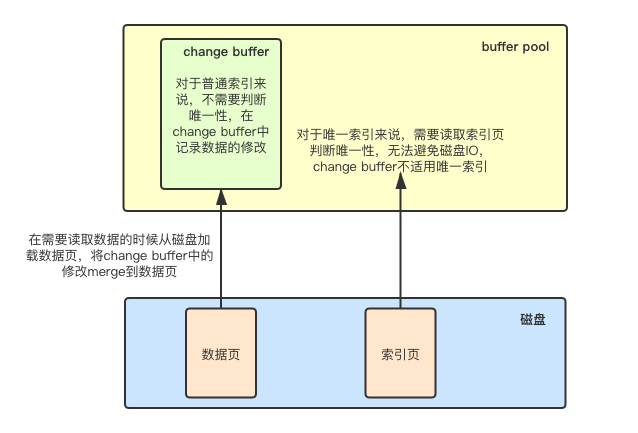
对于唯一索引,所有的更新操作必须要检查是否违法唯一约束,假如数据页不在buffer pool,必须要将数据页读入内存才可以判断(这里可以理解为读取索引页,通过索引判断唯一性),所以change buffer对于唯一索引并不适用。
change buffer是buffer pool的一部分,innodb_change_buffer_max_size参数可以设置其在buffer pool中的占比。
change buffer的适用场景:
适用于写多读少的场景,假如写入之后马上就要查询,即便已经将更新记录在了change buffer,由于需要查询,必须要从磁盘加载数据页才能读取到数据,然后触发merge操作,这样并不会减少磁盘的IO操作。
change buffer和redo log的侧重点:
change buffer主要是为了减少随机读磁盘的IO消耗。
redo log主要是为了减少随机写磁盘的IO消耗,redo log将磁盘的随机IO转为了顺序写,提升了速度。
参考:
救火队队长:从零开始带你成为MySQL实战优化高手
极客时间 — 林晓斌(丁奇):MySQL实战







没有回复内容