1.UUID作为全局ID
UUID(Universally Unique Identifier)是一种全局唯一标识符,它保证在空间和时间上的唯一性。通常由 128 位的数字组成,采用 32 位的十六进制数表示,格式为 8-4-4-4-12 这样的 36 个字符(32 个字母数字字符和 4 个短横线),例如 550e8400-e29b-41d4-a716-446655440000。 UUID 在 Java 中的实现如下:
import java.util.UUID;
public class UUIDExample {
public static void main(String[] args) {
UUID uuid = UUID.randomUUID();
System.out.println("Random UUID: " + uuid);
String uuidString = uuid.toString();
System.out.println("UUID as string: " + uuidString);
UUID parsedUuid = UUID.fromString(uuidString);
System.out.println("Parsed UUID: " + parsedUuid);
}
}
UUID 存在的问题
虽然 UUID 可以保证全局唯一,但并不推荐使用 UUID 来作为分库分表后的主键 ID,因为 UUID 有两个问题:
-
UUID 太长,且生成效率较低。
-
UUID 没有任何业务含义,不连续且没有任何顺序可言。
2.雪花ID作为全局ID
雪花 ID(Snowflake ID)是一个用于分布式系统中生成唯一 ID 的算法,由 Twitter 公司提出。它的设计目标是在分布式环境下高效地生成全局唯一的 ID,具有一定的有序性。 雪花 ID 的结构如下所示(共 64 位):这四部分代表的含义:
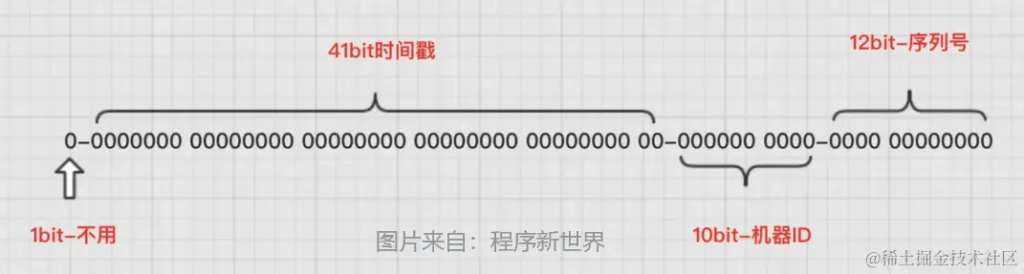
-
符号位:最高位是符号位,始终为 0,1 表示负数,0 表示正数,ID 都是正整数,所以固定为 0。
-
时间戳部分:由 41 位组成,精确到毫秒级。可以使用该 41 位表示的时间戳来表示的时间可以使用 69 年。
-
节点 ID 部分:由 10 位组成,用于表示机器节点的唯一标识符。在同一毫秒内,不同的节点生成的 ID 会有所不同。
-
序列号部分:由 12 位组成,用于标识同一毫秒内生成的不同 ID 序列。在同一毫秒内,可以生成 4096 个不同的 ID。
Java 版雪花算法实现
接下来,我们来实现一个 Java 版的雪花算法:
public class SnowflakeIdGenerator {
private static final long TIMESTAMP_BITS = 41L;
private static final long NODE_ID_BITS = 10L;
private static final long SEQUENCE_BITS = 12L;
private static final long EPOCH = 1609459200000L;
private static final long MAX_NODE_ID = (1L << NODE_ID_BITS) - 1;
private static final long MAX_SEQUENCE = (1L << SEQUENCE_BITS) - 1;
private static final long TIMESTAMP_SHIFT = NODE_ID_BITS + SEQUENCE_BITS;
private static final long NODE_ID_SHIFT = SEQUENCE_BITS;
private final long nodeId;
private long lastTimestamp = -1L;
private long sequence = 0L;
public SnowflakeIdGenerator(long nodeId) {
if (nodeId < 0 || nodeId > MAX_NODE_ID) {
throw new IllegalArgumentException("Invalid node ID");
}
this.nodeId = nodeId;
}
public synchronized long generateId() {
long currentTimestamp = timestamp();
if (currentTimestamp < lastTimestamp) {
throw new IllegalStateException("Clock moved backwards");
}
if (currentTimestamp == lastTimestamp) {
sequence = (sequence + 1) & MAX_SEQUENCE;
if (sequence == 0) {
currentTimestamp = untilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = currentTimestamp;
return ((currentTimestamp - EPOCH) << TIMESTAMP_SHIFT) |
(nodeId << NODE_ID_SHIFT) |
sequence;
}
private long timestamp() {
return System.currentTimeMillis();
}
private long untilNextMillis(long lastTimestamp) {
long currentTimestamp = timestamp();
while (currentTimestamp <= lastTimestamp) {
currentTimestamp = timestamp();
}
return currentTimestamp;
}
}
调用代码如下:
public class Main {
public static void main(String[] args) {
SnowflakeIdGenerator idGenerator = new SnowflakeIdGenerator(1);
long id = idGenerator.generateId();
System.out.println(id);
}
}
其中,nodeId 表示当前节点的唯一标识,可以根据实际情况进行设置。generateId 方法用于生成雪花 ID,采用同步方式确保线程安全。具体的生成逻辑遵循雪花 ID 的位运算规则,结合当前时间戳、节点 ID 和序列号生成唯一的 ID。
需要注意的是,示例中的时间戳获取方法使用了 System.currentTimeMillis(),根据实际需要可以替换为其他更精确的时间戳获取方式。同时,需要确保节点 ID 的唯一性,避免不同节点生成的 ID 重复。
雪花ID存在的问题
虽然雪花算法是一种被广泛采用的分布式唯一 ID 生成算法,但它也存在以下几个问题:
-
时间回拨问题:雪花算法生成的 ID 依赖于系统的时间戳,要求系统的时钟必须是单调递增的。如果系统的时钟发生回拨,可能导致生成的 ID 重复。时间回拨是指系统的时钟在某个时间点之后突然往回走(人为设置),即出现了时间上的逆流情况。
-
时钟回拨带来的可用性和性能问题:由于时间依赖性,当系统时钟发生回拨时,雪花算法需要进行额外的处理,如等待系统时钟追上上一次生成 ID 的时间戳或抛出异常。这种处理会对算法的可用性和性能产生一定影响。
-
节点 ID 依赖问题:雪花算法需要为每个节点分配唯一的节点 ID 来保证生成的 ID 的全局唯一性。节点 ID 的分配需要有一定的管理和调度,特别是在动态扩容或缩容时,节点 ID 的管理可能较为复杂。
如何解决时间回拨问题?
百度 UidGenerator 框架中解决了时间回拨的问题,并且解决方案比较经典,所以咱们这里就来给大家分享一下百度 UidGenerator 是怎么解决时间回拨问题的?
UidGenerator 介绍:UidGenerator 是百度开源的一个分布式唯一 ID 生成器,它是基于 Snowflake 算法的改进版本。与传统的 Snowflake 算法相比,UidGenerator 在高并发场景下具有更好的性能和可用性。它的实现源码在:
UidGenerator 是这样解决时间回拨问题的:UidGenerator 的每个实例中,都维护一个本地时钟缓存,用于记录当前时间戳。这个本地时钟会定期与系统时钟进行同步,如果检测到系统时钟往前走了(出现了时钟回拨),则将本地时钟调整为系统时钟。
小结







没有回复内容