4.1.1.6 兼容
-
向前兼容性:向前兼容性指的是旧版本的软件或硬件能够与将来推出的新版本兼容的特性,简而言之旧版本软件或系统兼容新的数据和流量。
-
向后兼容性:向后兼容性则是指新版本的软件或硬件能够与之前版本的系统或组件兼容的特性,简而言之新版本软件或系统兼容老的数据和流量。
4.1.2 存储层
4.1.2.1 复制
-
主从复制:客户端将所有写入操作发送到单个节点(主库),该节点将数据更改事件流发送到其他副本(从库)。读取可以在任何副本上执行,但从库的读取结果可能是陈旧的。
-
多主复制:客户端将每个写入发送到几个主库节点之一,其中任何一个主库都可以接受写入。主库将数据更改事件流发送给彼此以及任何从库节点。
-
无主复制:客户端将每个写入发送到几个节点,并从多个节点并行读取,以检测和纠正具有陈旧数据的节点。
4.1.2.2 分区
4.1.2.3 Redis 的复制和分片
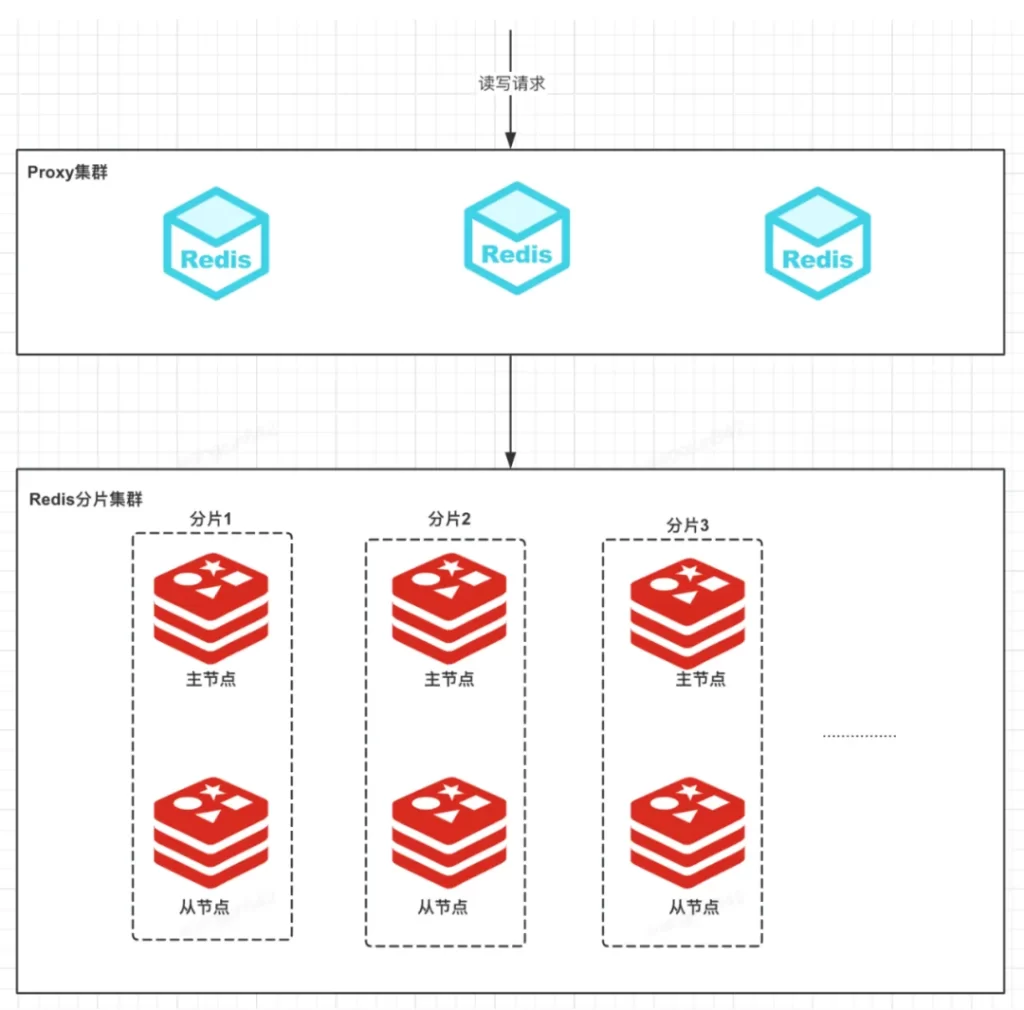
redis cluster集群中,我们会划分16384个槽,key 通过散列哈希算法会映射到相应的槽中,这些槽分配到不同的分片上,每个分片有主节点和从节点,主节点对外提供读写服务,从节点对外提供读服务。当某个分片的主节点挂掉,其他分片的主节点会从挂掉分片的从节点选择一个作为主节点继续对外提供服务。整体的架构如下图所示。
4.1.2.4 ES索引的复制和分片
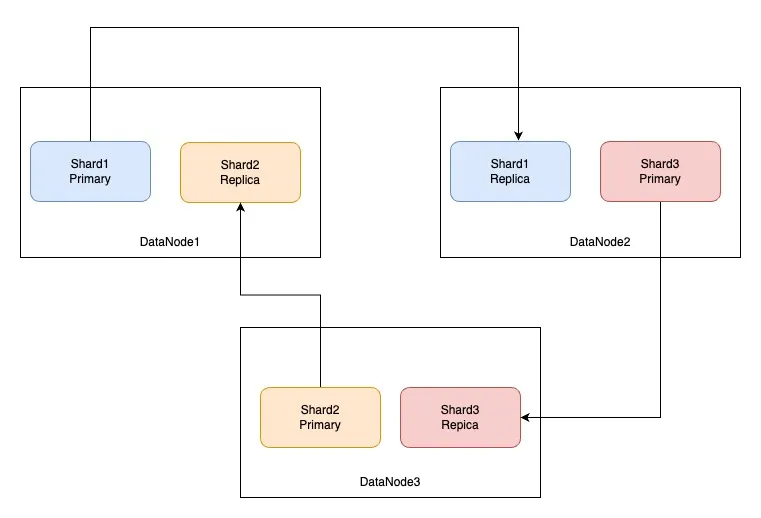
我们在创建ES索引时,会指定分片的数量和副本的数量,分片的数量确定后是不允许修改的,副本的数量允许修改,分片的数量一般和数据节点的数量保持一致,这样能将索引的数据分配到每个数据节点上,每个数据节点都存储索引的部分数据,Primary分片可以对外提供读写服务,Replica分片对外提供读服务的同时作为备份节点保证可用性,ES索引的不同分片在不同数据节点的分布如下图所示。
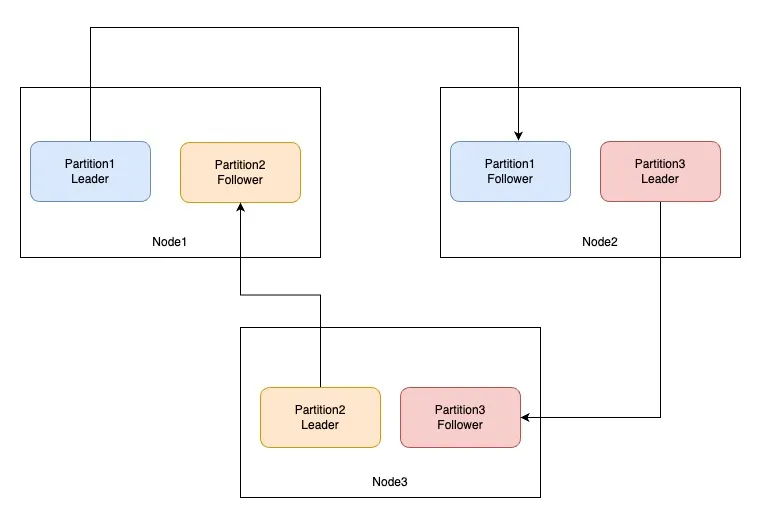
4.1.2.5 Kafka topic的复制和分区
4.1.3 部署层
4.1.3.1 业界部署架构的演进
部署层是通过不断突破单机器,单机房,单地域,做到机器级别,机房级别,地域级别的容灾来保证系统的高可用。核心思想是通过冗余以及负载均衡进行容灾保证高可用。
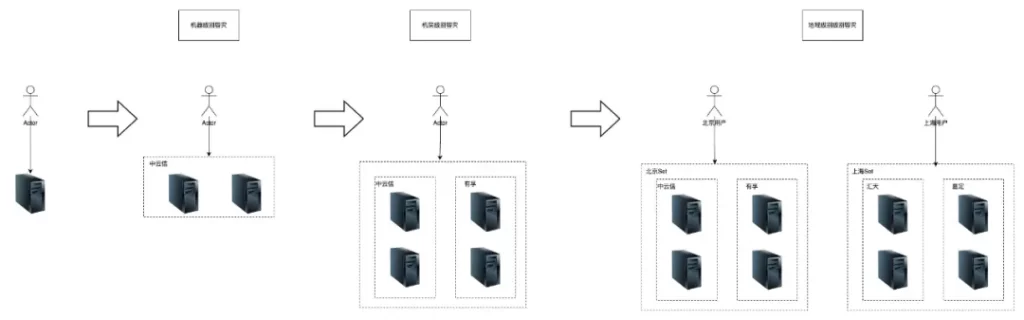
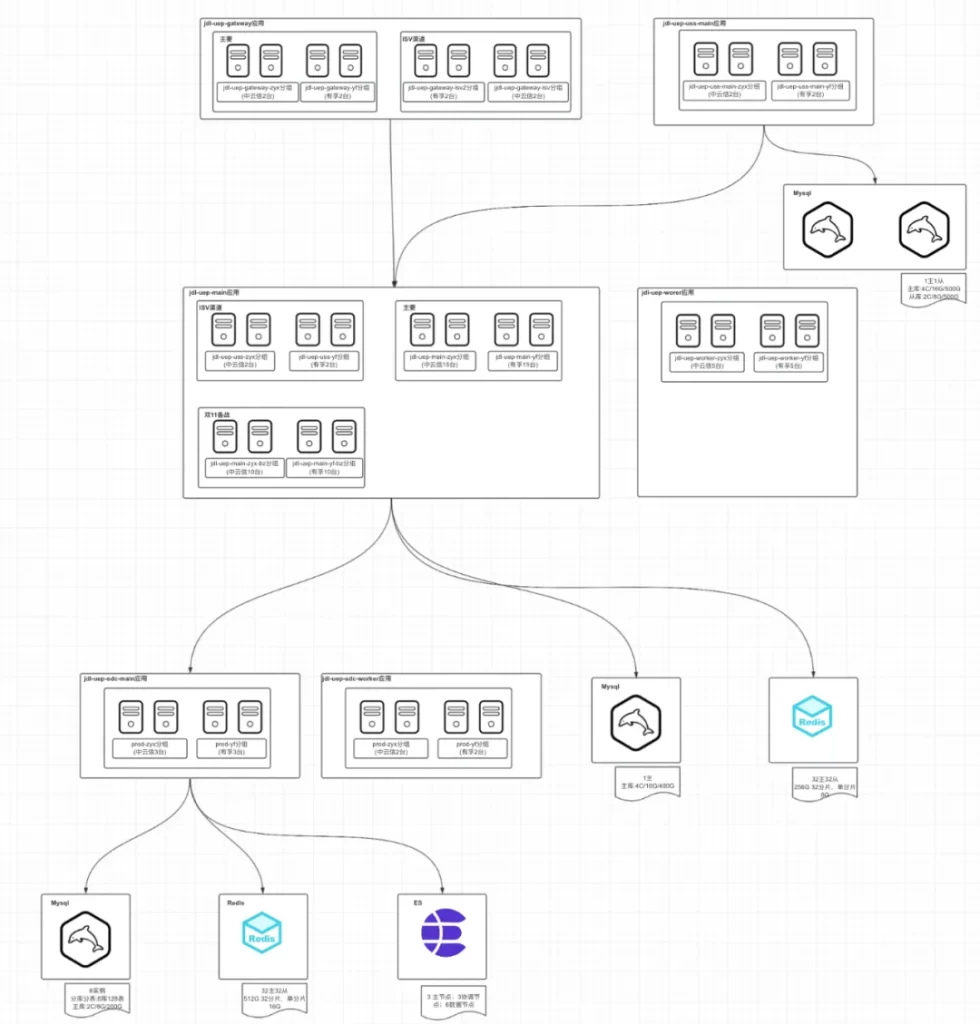
4.1.3.2 我们部署架构现状
-
应用容器机房为:中云信,有孚,廊坊,宿迁等;
-
数据库Mysql双机房部署:中云信,有孚;
-
缓存Redis双机房部署:中云信,有孚;
-
ES单机房部署:有孚。
总结
软件的发展历程就像一场与复杂性对抗的持久战,这场战争主要围绕着两个主要的战场:技术复杂性和业务复杂性。在这篇文章中,我从后端研发的视角出发,深入探讨多年来来我在B\C端系统建设方面的宝贵经验和实践,特别关注那些需要同时应对高性能、高并发和高可用性的系统设计和优化策略,希望和大家多多交流,相互探讨。
来源https://mp.weixin.qq.com/s/KexjVJOsGYN50MxqzVT3mA







没有回复内容