LinkedHashMap 简介
LinkedHashMap 是 Java 提供的一个集合类,它继承自 HashMap,并在 HashMap 基础上维护一条双向链表,使得具备如下特性:
- 支持遍历时会按照插入顺序有序进行迭代。
- 支持按照元素访问顺序排序,适用于封装 LRU 缓存工具。
- 因为内部使用双向链表维护各个节点,所以遍历时的效率和元素个数成正比,相较于和容量成正比的 HashMap 来说,迭代效率会高很多。
LinkedHashMap 逻辑结构如下图所示,它是在 HashMap 基础上在各个节点之间维护一条双向链表,使得原本散列在不同 bucket 上的节点、链表、红黑树有序关联起来。
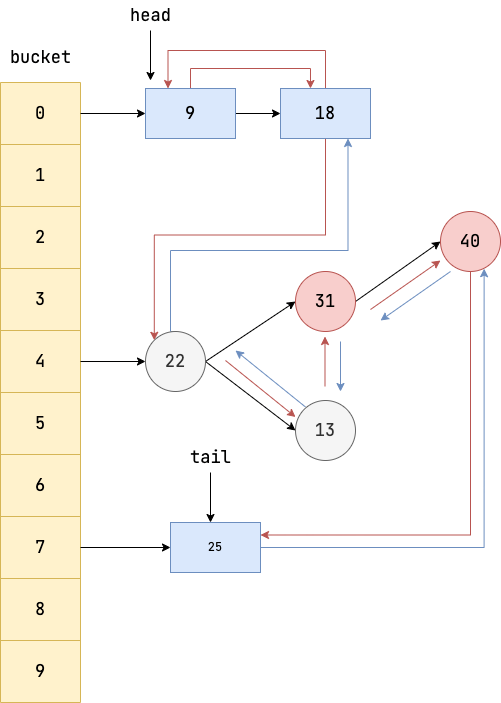
LinkedHashMap 使用示例
插入顺序遍历
如下所示,我们按照顺序往 LinkedHashMap 添加元素然后进行遍历。
HashMap < String, String > map = new LinkedHashMap < > ();
map.put("a", "2");
map.put("g", "3");
map.put("r", "1");
map.put("e", "23");
for (Map.Entry < String, String > entry: map.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}输出:
a:2
g:3
r:1
e:23可以看出,LinkedHashMap 的迭代顺序是和插入顺序一致的,这一点是 HashMap 所不具备的。
访问顺序遍历
LinkedHashMap 定义了排序模式 accessOrder(boolean 类型,默认为 false),访问顺序则为 true,插入顺序则为 false。
为了实现访问顺序遍历,我们可以使用传入 accessOrder 属性的 LinkedHashMap 构造方法,并将 accessOrder 设置为 true,表示其具备访问有序性。
LinkedHashMap<Integer, String> map = new LinkedHashMap<>(16, 0.75f, true);
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
map.put(4, "four");
map.put(5, "five");
//访问元素2,该元素会被移动至链表末端
map.get(2);
//访问元素3,该元素会被移动至链表末端
map.get(3);
for (Map.Entry<Integer, String> entry : map.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}输出:
1 : one
4 : four
5 : five
2 : two
3 : three可以看出,LinkedHashMap 的迭代顺序是和访问顺序一致的。
LRU 缓存
从上一个我们可以了解到通过 LinkedHashMap 我们可以封装一个简易版的 LRU(Least Recently Used,最近最少使用) 缓存,确保当存放的元素超过容器容量时,将最近最少访问的元素移除。
![图片[2]-Java LinkedHashMap 介绍(一)-Java专区论坛-技术-SpringForAll社区](https://oss.javaguide.cn/github/javaguide/java/collection/lru-cache.png)
具体实现思路如下:
- 继承
LinkedHashMap; - 构造方法中指定
accessOrder为 true ,这样在访问元素时就会把该元素移动到链表尾部,链表首元素就是最近最少被访问的元素; - 重写
removeEldestEntry方法,该方法会返回一个 boolean 值,告知LinkedHashMap是否需要移除链表首元素(缓存容量有限)。
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private final int capacity;
public LRUCache(int capacity) {
super(capacity, 0.75f, true);
this.capacity = capacity;
}
/**
* 判断size超过容量时返回true,告知LinkedHashMap移除最老的缓存项(即链表的第一个元素)
*/
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > capacity;
}
}测试代码如下,笔者初始化缓存容量为 3,然后按照次序先后添加 4 个元素。
LRUCache<Integer, String> cache = new LRUCache<>(3);
cache.put(1, "one");
cache.put(2, "two");
cache.put(3, "three");
cache.put(4, "four");
cache.put(5, "five");
for (int i = 1; i <= 5; i++) {
System.out.println(cache.get(i));
}输出:
null
null
three
four
five从输出结果来看,由于缓存容量为 3 ,因此,添加第 4 个元素时,第 1 个元素会被删除。添加第 5 个元素时,第 2 个元素会被删除。
LinkedHashMap 源码解析
Node 的设计
在正式讨论 LinkedHashMap 前,我们先来聊聊 LinkedHashMap 节点 Entry 的设计,我们都知道 HashMap 的 bucket 上的因为冲突转为链表的节点会在符合以下两个条件时会将链表转为红黑树:
链表上的节点个数达到树化的阈值 7,即TREEIFY_THRESHOLD - 1。- bucket 的容量达到最小的树化容量即
MIN_TREEIFY_CAPACITY。
🐛 修正:
链表上的节点个数达到树化的阈值是 8 而非 7。因为源码的判断是从链表初始元素开始遍历,下标是从 0 开始的,所以判断条件设置为 8-1=7,其实是迭代到尾部元素时再判断整个链表长度大于等于 8 才进行树化操作。
![图片[3]-Java LinkedHashMap 介绍(一)-Java专区论坛-技术-SpringForAll社区](https://camo.githubusercontent.com/3246fc1fb03da7060403c113985f7593164a706ba443cee046913e4ba127fde5/68747470733a2f2f6f73732e6a61766167756964652e636e2f6769746875622f6a61766167756964652f6a6176612f6a766d2f4c696e6b6564486173684d61702d70757476616c2d545245454946592e706e67)
![图片[3]-Java LinkedHashMap 介绍(一)-Java专区论坛-技术-SpringForAll社区](https://oss.javaguide.cn/github/javaguide/java/jvm/LinkedHashMap-putval-TREEIFY.png)
而 LinkedHashMap 是在 HashMap 的基础上为 bucket 上的每一个节点建立一条双向链表,这就使得转为红黑树的树节点也需要具备双向链表节点的特性,即每一个树节点都需要拥有两个引用存储前驱节点和后继节点的地址,所以对于树节点类 TreeNode 的设计就是一个比较棘手的问题。
对此我们不妨来看看两者之间节点类的类图,可以看到:
LinkedHashMap的节点内部类Entry基于HashMap的基础上,增加before和after指针使节点具备双向链表的特性。HashMap的树节点TreeNode继承了具备双向链表特性的LinkedHashMap的Entry。
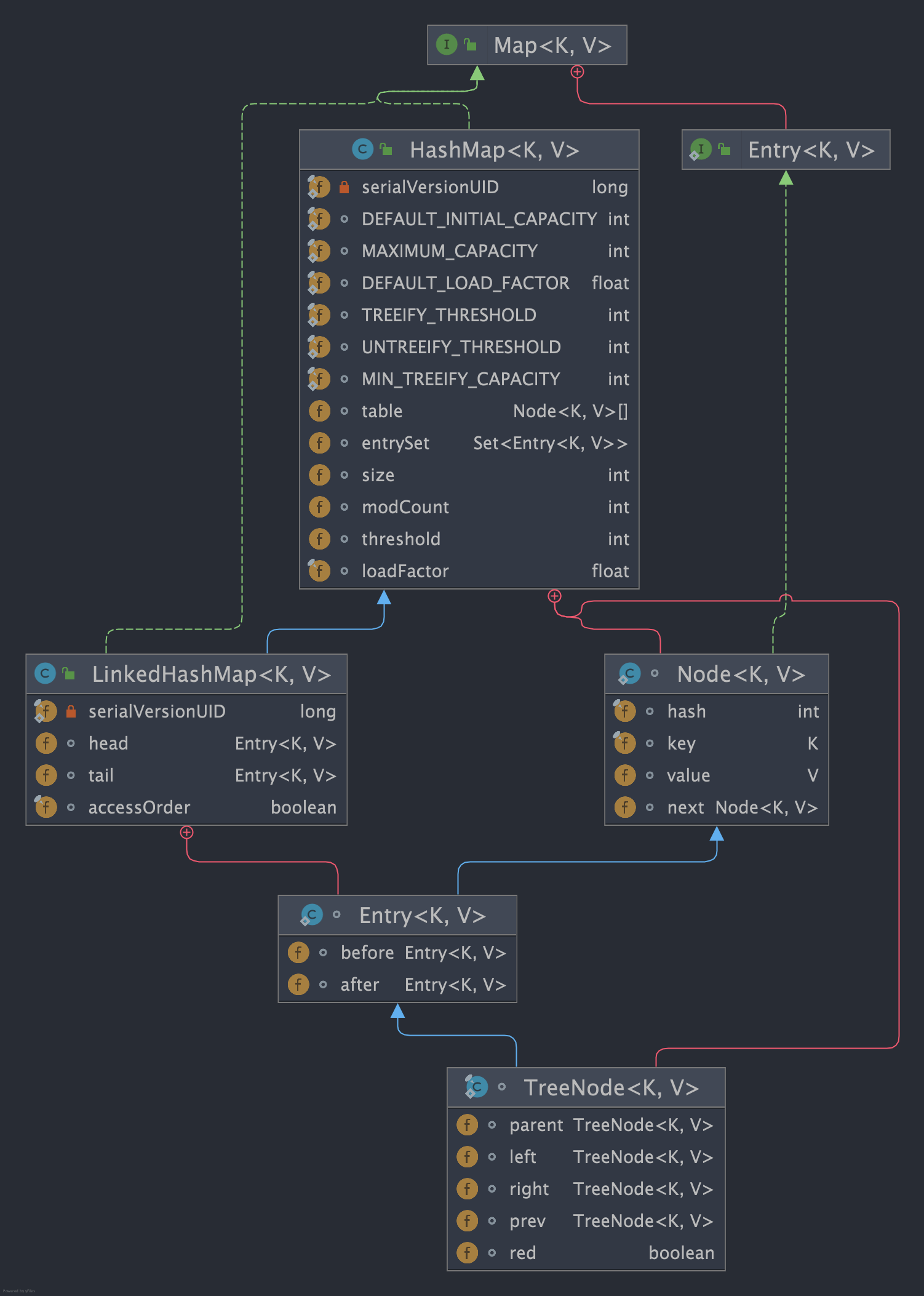
很多读者此时就会有这样一个疑问,为什么 HashMap 的树节点 TreeNode 要通过 LinkedHashMap 获取双向链表的特性呢?为什么不直接在 Node 上实现前驱和后继指针呢?
先来回答第一个问题,我们都知道 LinkedHashMap 是在 HashMap 基础上对节点增加双向指针实现双向链表的特性,所以 LinkedHashMap 内部链表转红黑树时,对应的节点会转为树节点 TreeNode,为了保证使用 LinkedHashMap 时树节点具备双向链表的特性,所以树节点 TreeNode 需要继承 LinkedHashMap 的 Entry。
再来说说第二个问题,我们直接在 HashMap 的节点 Node 上直接实现前驱和后继指针,然后 TreeNode 直接继承 Node 获取双向链表的特性为什么不行呢?其实这样做也是可以的。只不过这种做法会使得使用 HashMap 时存储键值对的节点类 Node 多了两个没有必要的引用,占用没必要的内存空间。
所以,为了保证 HashMap 底层的节点类 Node 没有多余的引用,又要保证 LinkedHashMap 的节点类 Entry 拥有存储链表的引用,设计者就让 LinkedHashMap 的节点 Entry 去继承 Node 并增加存储前驱后继节点的引用 before、after,让需要用到链表特性的节点去实现需要的逻辑。然后树节点 TreeNode 再通过继承 Entry 获取 before、after 两个指针。
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}但是这样做,不也使得使用 HashMap 时的 TreeNode 多了两个没有必要的引用吗?这不也是一种空间的浪费吗?
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
//略
}对于这个问题,引用作者的一段注释,作者们认为在良好的 hashCode 算法时,HashMap 转红黑树的概率不大。就算转为红黑树变为树节点,也可能会因为移除或者扩容将 TreeNode 变为 Node,所以 TreeNode 的使用概率不算很大,对于这一点资源空间的浪费是可以接受的。
Because TreeNodes are about twice the size of regular nodes, we
use them only when bins contain enough nodes to warrant use
(see TREEIFY_THRESHOLD). And when they become too small (due to
removal or resizing) they are converted back to plain bins. In
usages with well-distributed user hashCodes, tree bins are
rarely used. Ideally, under random hashCodes, the frequency of
nodes in bins follows a Poisson distribution