假如您有一个 10 GB 的银行事务日志文件,其中包含各个事务的记录。您的任务是处理文件,筛选出金额高于 10,000 的交易,然后对金额求和。由于文件很大,因此目标是使用并行性高效处理它,以加快计算速度。
Parallel Streams方法
在 Java 中,Stream API 允许对数据进行顺序和并行处理。使用并行流时,Java 会将数据分成多个部分,并利用 CPU 的多个内核在不同的线程上同时处理它们。此方法对于大型数据集特别有用,因为可以通过划分工作来减少处理时间。
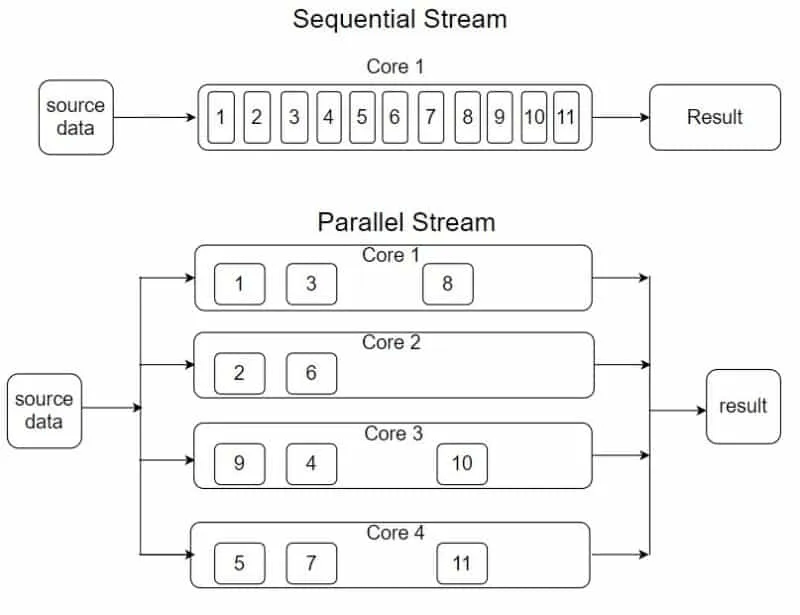
Parallel Streams 的工作原理
- 拆分数据:当您使用并行流时,Java 会自动将数据分区为可以独立处理的块。这些分区在多个 CPU 内核上处理。
- 并行处理:每个数据块由不同的线程并行处理。Java 在后台使用 Fork/Join 框架来实现并行性。
- 合并结果:处理完所有数据块后,结果将被合并(减少)以产生最终结果。在您的情况下,它将对大于 10,000 的事务金额求和。
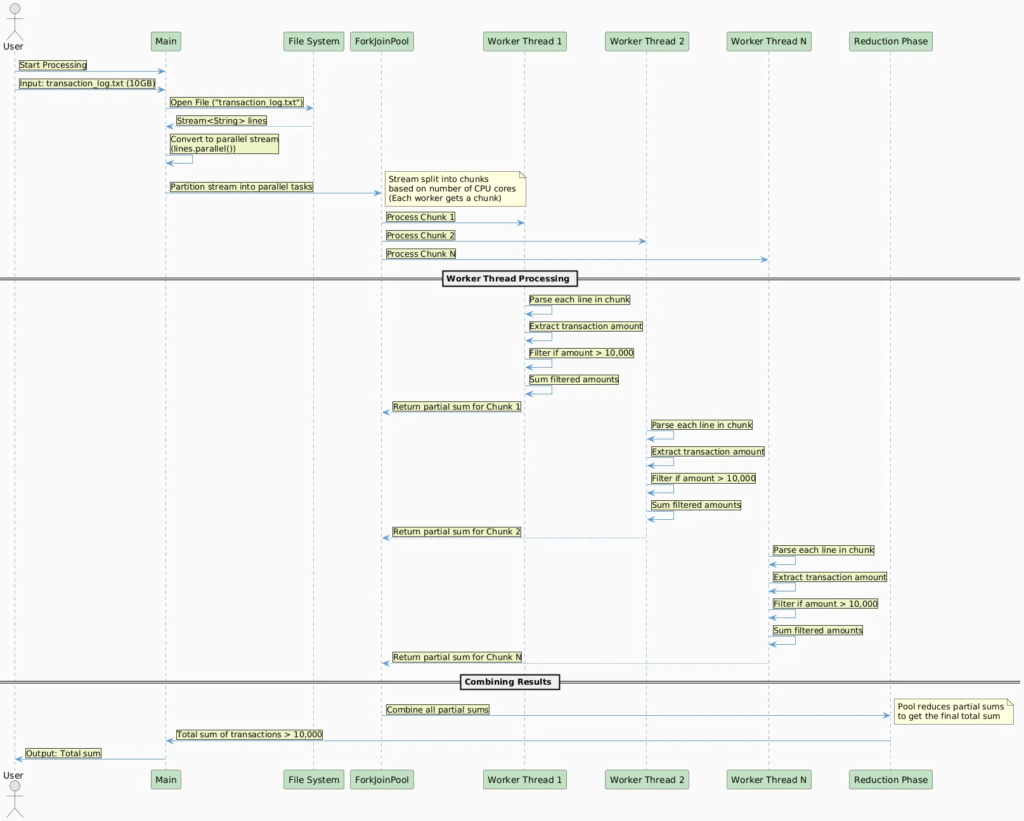
使用并行流处理 10 GB 文件
并行读取文件:您可以使用 Files.lines() 读取文件,这将延迟流式传输文件的行(无需一次将整个文件加载到内存中)。之后,可以使用 .parallel() 将流转换为并行流。
解析与筛选:事务日志中的每一行都包含事务详细信息,例如事务金额。您需要解析每一行,提取金额,并筛选出金额大于 10,000 的交易。
对金额求和:筛选后,使用 reduce() 或 sum() 等终端操作对交易金额求和。
public class TransactionProcessor {
public static void main(String[] args) throws Exception {
// Path to the large 10GB transaction log file
String filePath = "path/to/transaction_log.txt";
// Process the file in parallel, filter and sum the transactions greater than 10000
double total = Files.lines(Paths.get(filePath)) // Stream of lines from the file
.parallel() // Convert to parallel stream
.map(TransactionProcessor::parseTransactionAmount) // Parse the amount from each line
.filter(amount -> amount > 10000) // Filter transactions greater than 10000
.mapToDouble(Double::doubleValue) // Convert Stream<Double> to DoubleStream
.sum(); // Sum the filtered amounts
System.out.println("Total sum of transactions greater than 10,000: " + total);
}
// Helper method to parse transaction amount from a line (assuming a specific format)
private static Double parseTransactionAmount(String line) {
// Assuming the transaction log is in CSV format with the amount as the second column
// For example: "txn_id,amount,timestamp"
String[] fields = line.split(",");
return Double.parseDouble(fields[1]); // Extract the amount
}
}使用并行流的优点
提高性能:通过使用并行流,文件可以由多个线程同时处理,从而利用多核 CPU 的全部功能。与顺序处理相比,这大大减少了总处理时间。
可扩展性:随着文件大小的增长或 CPU 内核数量的增加,并行流可以跨可用资源扩展计算。
声明性代码:并行流提供了一种简洁的声明性方法来编写并行处理逻辑,而无需手动管理线程,这会增加复杂性。
性能注意事项
IO 瓶颈:由于文件是从磁盘读取的,因此性能可能会受到磁盘速度的限制。使用并行流可以加快处理速度,但如果磁盘无法足够快地提供数据,这仍然可能成为瓶颈。
线程管理:JVM 会自动管理具有并行流的线程,但您可以根据需要使用 ForkJoinPool 微调线程池大小。默认情况下,线程池大小等于 CPU 内核数。
垃圾回收:处理具有许多对象的大文件(例如将文件拆分为字符串)可能会给垃圾回收器带来压力。确保 JVM 具有足够的内存并进行调优来处理此负载。
其他挑战
线程同步:虽然 Fork/Join 框架抽象了大部分复杂性,但确保并行流内的处理逻辑是无状态且线程安全的仍然很重要。由于每个线程都在自己的分区上工作,因此同步通常不是问题,但需要注意。
文件格式:如果文件格式不正确(例如,行中的字段数不一致),则在解析过程中可能会引发异常。在这种情况下,需要额外的错误处理和验证。
数据拆分:当文件可以轻松划分为独立的块时(例如,当行表示独立事务时),并行处理的性能提升会更大。如果数据在行之间具有依赖关系,则并行处理会变得更加复杂。
总结
使用并行流是在 Java 中处理大型文件的一种有效方法,尤其是对于可以轻松并行化的任务,例如对大于一定数量的银行交易求和。它利用多核处理器来提高性能,并通过在多个线程之间分配工作负载来减少处理大型数据集所需的时间。







没有回复内容