一、1.5B/7B/8B版本
-
模型定位:中小型模型、轻量级模型、平衡型模型 -
参数规模:1.5B(15亿)、7B(70亿)、8B(80亿)。 -
特点:轻量级模型,资源消耗低,推理速度快,但处理复杂任务的能力有限。 -
硬件需求:普通消费级GPU(如RTX 3090/4090,显存≥4GB)即可部署。 -
典型适用场景: -
本地开发和测试:可处理一些常规的翻译、总结、摘要、生成等常见任务。 -
轻量级应用:常规智能助手、常规文本生成工具(如摘要生成、基础问答)、轻量级多轮对话系统等。 -
实时性要求高的场景:用于某些资源受限的环境下所使用。
-
二、14B/32B版本
-
模型定位:大型模型、高性能模型、专业型模型
-
参数规模:14B(140亿)、32B(320亿)。
-
特点:中等规模模型,推理能力显著提升,支持复杂逻辑推理和代码生成。
-
硬件需求:高端GPU(如RTX 4090/A5000,显存≥16GB)。
-
典型适用场景:
-
中高等复杂任务:长文本理解生成、高级别文本翻译、高级别文本分析、专业领域的知识图谱构建等需要较高精度的任务。
-
专业开发工具:如专业型数据分析(如辅助编程或企业级文档处理)、深度内容分析处理等。
-
三、70B/671B版本
-
模型定位:超大规模模型、顶级模型
-
参数规模:70B(700亿)、671B(6710亿)。
-
特点:顶级大模型,擅长复杂推理和海量数据处理。
-
硬件需求:大规模云端计算集群(如多卡A100/H100 GPU,显存≥80GB)。
-
典型适用场景:
-
科研与高精度任务:如医学数据分析、复杂数学证明、战略决策支持等。
-
云端服务:大型企业的数据挖掘、大型企业的前沿探索、超长超复杂内容处理等。
-
这里也有一张表格,比较直观地阐述了各个版本性能、速度以及成本对比,相信这样看起来就非常易于理解和比较了。
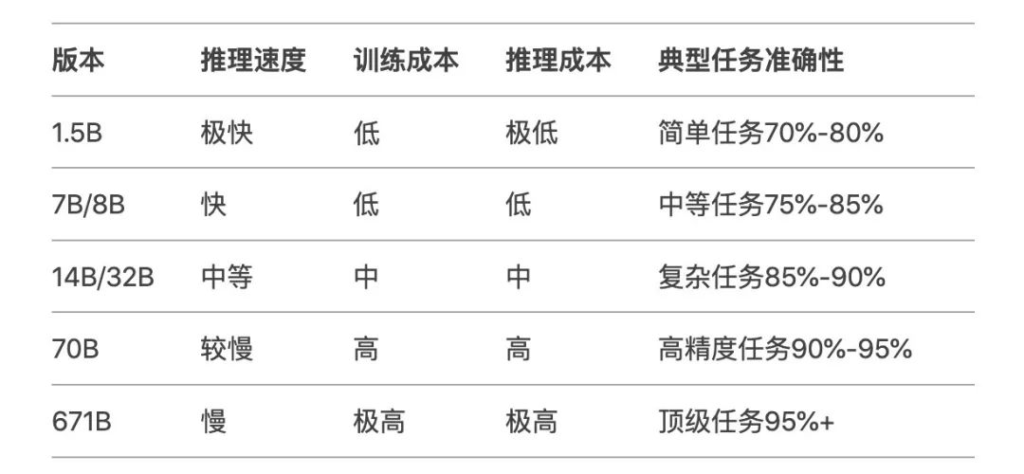
所以如果要应用于轻量级应用场景,有快速响应需求并且资源有限的话,可以选择类似 1.5B、7B 这样的中小模型,可以快速加载运行推理;
对于普通用户来说,其实7B~14B版本就已经能满足大多数常规需求,处理一些常见任务不成问题;
而像70B版本、671B满血版这种则可以为更高精度科研、商业分析等高精度任务和顶级任务提供支持。
接下来我们再来看一份 DeepSeek-R1-xx 各个常见不同版本在本地部署时对于机器硬件配置的对比表格。
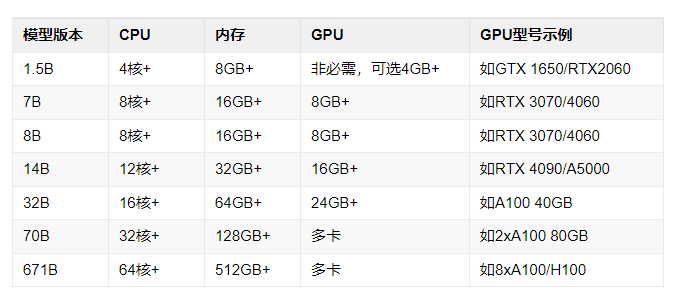
以上清单所列的配置仅仅是对应版本部署时的典型值,部分数据基于模型通用需求推测,并非绝对的参数要求。总体来说,数据是比很多用户在本地实际部署时的配置要写得高一些的,这点需要注意。
用户在实际部署时,如果可以稍微接受一些效果或者体验上的浮动,那对应的硬件配置参数再下一档问题应该也不大,所以最终还是在于用户对于使用的要求以及硬件资源的取舍和权衡。
大家也可以多实验,多尝试,最终的实际情况还得以自己的实测部署结果以及使用效果为准。







没有回复内容